|
|
|
|
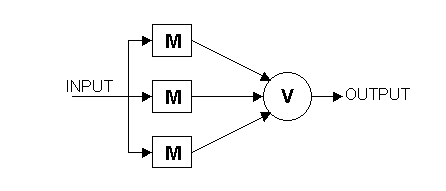
In questa sezione vengono analizzati delle tecniche che permettono di realizzare un hardware tollerante ai guasti. I meccanismi esposti sono tolleranti ai guasti fisici e non a errori di progetto. La triple modular redundancy (TMR) [12] è la tecnica più conosciuta di tolleranza ai guasti a livello hardware e viene utilizzata in molti sistemi tolleranti ai guasti. I concetti di funzionamento sono stati introdotti da Von Neumann. Nella TMR l’unità hardware (rappresentata da M nella figura) è triplicata e le tre unità lavorano in parallelo ricevendo gli stessi ingressi. L’output di queste tre unità è passato all’arbitro chiamato voting element (rappresentato da V nella figura) che determina il valore dell’output, che è quello ottenuto da almeno due unità. Chiaramente la TMR è in grado di mascherare completamente il guasto di una unità hardware senza dover intraprendere nessuna procedura di ripristino. Il TMR è particolarmente utile nel caso di guasti transitori, dal momento che il TMR non rimuove l’unità guasta dal sistema quando un errore occorre. Questo meccanismo non è in grado di coprire il guasti di due unità hardware, infatti quando una unità si guasta è essenziale che le altre due continuino a lavorare correttamente in modo che l’arbitro sia in grado di stabilire un maggioranza. Se però l’arbitro applica il meccanismo di voting bit per bit, è in grado di correggere un errore doppio se avvenuto su due bit differenti. Il punto critico in questa struttura è l’arbitro: Cosa succede se il guasto è nel voting element? Si possono utilizzare delle strutture che risolvono questo problema introducendo una ridondanza anche negli arbitri. Una generalizzazione del TMR è NMR, che replica N volte l’unità hardware, e quindi è in grado di correggere errori multipli.
Un sistema a ridondanza dinamica [12] è formato da un certo numero di unità uguali, ma con una sola attiva alla volta. Le altre unità, non attive, sono di riserva, se una delle unità operanti si guasta viene disattivata e si prende una delle unità di riserva e la si rende attiva.
Il problema principale di questo approccio è come individuare che una unità è guasta. Viene solitamento fatto in tre modi:
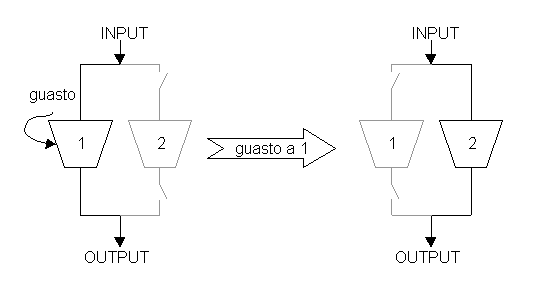
IL sistema con ridondanza dinamica può essere classificato come cold-standby o hot-standby, a secondo di come le unità di riserva sono trattate. Nei sistemi cold-standby una sola unità e alimentata e operativa, quelle di riserva non sono alimentate, una unità guasta è rimpiazzata togliendo l’alimentazione e alimentandone una di riserva. Nei sistemi hot-standby tutte le unità operano simultaneamente, se gli output si prende a caso l’uscita di una unità, se invece sono diversi si isola l’unità guasta e si riconfigura il sistema prendendo l’uscità di una unità di riserva (la differenza sostanziale con il TMR sta nel modo di individuare e rimuvere l’unità guasta). Il più comune sistema hot-standby è quello che utilizza due unità in parallelo ed è chiamato sistema duplex. Un circuito di matching compara i risultati delle due unità, se sono diversi viene lanciato un programma di diagnosi per localizzare il guasto, la riconfigurazione viene fatta andando a disattivare il circuito guasto.
Al giorno d’oggi, il tasso d’errore associato ai sistemi digitali è estremamente basso, al confronto dell’aumento della velocità di trasmissione e di processamento. Gli sviluppi in materia di codice di correzione di errore hanno contribuito ad avere sistemi altamente affidabili, quindi è evidente che essi sono diventati una parte integrale dei moderni sistemi di computer e di comunicazione. Il codice non è altro che la rappresentazione di informazione (di qualunque tipo) per mezzo di simboli di codice o loro sequenze (spesso chiamate "parole di codice"); la mappatura di questi simboli caratterizza il codice. L’informazione è messa in forma di codice con l’operazione di codifica ed estratta con la decodifica. Alcuni codici introducono ridondanza, che è usata per una correzione di errore. Il primo ad introdurre codici con ridondanza è stato Shannon, il quale ha dimostrato che in un canale rumoroso gli errori possono essere ridotti fino ad un livello desiderato introducendo un certa percentuale di ridondanza quando si codifica l’informazione. Sebbene egli non ha dato alcun algoritmo, ma solo un teorema, altri lavori (Golay, Hamming, Slepian, Prange, Peterson, Lucky, Salz, Prange) hanno dato fondamentali apporti per costruire le fondamentali strutture matematiche che sono alla base del moderno controllo di errore. Il codice di sorgente [1] non è altro che la rappresentazione digitale di informazione e non necessita di un controllo di errore. Normalmente si cerca di rappresentare l’informazione nel modo più efficiente, ad esempio utilizzando il numero minore possibile di simboli di codice. Il codice di sorgente è utilizzato di solito per rappresentare l’informazione in uscita ad una fonte, solo in seguito se l’informazione è trasmessa o memorizzata allora si può introdurre uno schema per la codifica d’errore. Un importante classe di codici che controllano gli errori sono i codici di blocco, che consistono in parole di codice, cioè sequenze di simboli di lunghezza fissa n. Nella maggior parte dei casi la sequenza di informazione è codificata in k simboli, che poi sono codificati come parole di n cifre. In questo caso la ridondanza è definita come ( n – k ) / n. Un tipo di codice di blocco così ottenuto è di solito indicato come codice ( n, k ). I codici binari [1] sono di gran lunga i più importanti codici utilizzati in informatica, per la trasmissione, la memorizzazione, e il processamento di informazione. Nel processo di trasmissione o immagazzinamento dell’informazione, possiamo vedere come vari tipi di codice possono intervenire. Prima di tutto c’è la codifica di sorgente, il cui scopo è quello di produrre la migliore rappresentazione dei dati originati dalla sorgente di informazione. A questo livello se la sorgente è analogica, è anche presente la quantizzazione del segnale analogico. A questo punto il codificatore di controllo di errore (o di canale), inserisce la necessaria ridondanza (il cui modello si basa sulla statistica del mezzo trasmissivo su cui di solito è presente rumore; di solito una ipotesi molto realistica è quella di un canale senza memoria del passato (Shannon) o con memoria dell’ultimo stato (Markov), raramente bisogna ricorrere a modelli più complicati (Mandelbrot)). L’informazione così ottenuta è pronta per essere trasformata in una grandezza fisica trasmissibile e quindi essere trasmessa. Il ricevente dovrà fare tutte le operazioni inverse. In questo modello semplificato, gli errori che possono essere introdotti sono: rumore circuitale (del modulatore e demodulatore principalmente) di origine termica; disturbi fisici sulla linea trasmissiva (es. scariche elettriche, rumore di fondo) o nel mezzo di immagazzinamento (es. polvere, smagnetizzazione del supporto). Le strutture matematiche alla base dei codici sono abbastanza semplici. Se è possibile separare un codice in due parti, la parte contente informazione e la parte di ridondanza, allora si chiama codice separabile. Nei codici separabili lineari [1], ogni simboli di controllo è esprimibile come una combinazione lineare dei simboli di informazione(es. il bit di parità, è uno dei codici di questo tipo più semplici). Di solito viene usata una notazione matriciale per schematizzare questo processo. L’altra grande famiglia di codici sono i codici polinomiali ciclici. In questo caso i caratteri di informazione sono usati come i coefficienti di un polinomio, i cui termini sono poi pesati da opportuni pesi (es. tutti i codici CRC). Dal punto di vista funzionale, si possono quindi avere alcune classi di codici, in questa categoria:
Quando si pianifica la strategia di codifica da utilizzare, bisogna tenere conto non solo della capacità e efficienza del codice utilizzato, ma anche delle risorse necessarie e di quanto tempo e spazio utilizzo. Ad esempio più è lungo il blocco di codice usato, più è grande la classe di errori che esso è in grado di correggere, ma è anche vero che i circuiti di codifica, di decodifica diventano più complessi, che viene richiesta più memoria e che il ritardo dovuto alla computazione aumenta. In questo caso è necessario chiedersi se, con una più accurata stima degli errori del canale, non è possibile prevedere quelli più frequenti, e utilizzare quindi codici a minore ridondanza che mantengano comunque la stessa affidabilità. Inoltre bisogna vedere quali sono le nostre esigenze: abbiamo vincoli di velocità o di elevata robustezza? E per quanto riguarda gli errori? Come vogliamo trattarli? Ci basta scoprire l’errore o vogliamo correggerlo? E in caso di correzione, vogliamo una correzione parziale o totale? Seguendo le risposte a queste domande, abbiamo diverse categorie di codici. I codici che ci permettono solo di scoprire un errore, sono i più semplici da implementare (di solito questa funzionalità è già contenuta nelle categorie successive di codici), e di solito prevedono un feedback di canale, che informi chi ha trasmesso dell’errore e quindi proceda alla ritrasmissione. In generale questa classe di codici può andar bene per errori concentrati nel tempo e non per errori casuali o comunque ripetitivi. I codici che ci permettono una parziale correzione, sono più complessi perché permettono sia di correggere uno o più errori, sia di rilevare un certo numero di altri errori. Questi codici, utilizzati assieme alla ritrasmissione, consentono un ottimo metodo per una trasmissione di qualità elevata, anche in presenza di canale molto rumoroso. Un altro problema è quello delle cancellazioni ovvero di segnali di cui non si conosce effettivamente il livello, ovvero se sono 1 o 0. Con un codice di errore che corregge t errori, è possibile correggere fino a 2t cancellazioni, se si suppone che le cancellazioni siano singole. Infine è possibile utilizzare schemi di codifica adattativa (che si adatta alle variazioni nel tempo degli errori), basata anche questa sulla possibilità di ritrasmissione (anche se recentemente è stata studiata una metodologia che non lo prevede); oppure codifiche successive.
|