|
|
|
|
Il software non ha proprietà fisiche, è una entità puramente concettuale, e quindi un guasto non può essere dovuto ad un degradamento fisico come invece avviene nell’hardware. Gli errori nel software (bugs) sono sempre degli errori di progetto. Un programma è formato da diversi componenti, ognuno dei quali è un modulo o un sottoprogramma. Alcuni di questi componenti possono essere difettosi, l’obiettivo dei software tolleranti ai guasti è di assicurare che il sistema software continui a funzionare correttamente nonostante la presenza di componenti difettosi. Si intuisce che la replicazione di una stesso componente non può essere d’aiuto, in quanto presenterà lo stesso tipo di errore. Nell’hardware si utilizza la replicazione in quanto si assume che il progetto sia corretto, e l’obiettivo è quello di mascherare gli errori causati da fenomeni fisici (es. rottura di un transistor). Quindi per far fronte ad errori di progetto è necessario avere dei componenti progettati diversamente, possibilmente da gruppi di lavoro diversi. Il maggior inconveniente di una progettazione multipla è il costo, infatti il costo più influente dello sviluppo di un sistema software si ha nella fase di progettazione. Questo meccanismo corrisponde all’approccio NMR usato nell’hardware esposto nel paragrafo 2.1. L’uso di computazione multiplo è la base per supportare la tolleranza ai guasti. La programmazione N-Version è definita come "l’indipendente generazione di N³ 2 programmi funzionalmente equivalenti, chiamati versioni, a partire dalle stesse specifiche" [12,15]. Le N versioni sono realizzate da gruppi di lavoro differenti che non interagiscono fra loro, in modo da non introdurre gli stessi errori di progetto. Dove possibile vengono usati differenti compilatori. Quando N=2 si individua solamente la presenza di un errore, ma non è possibile la correzione se non con altri meccanismi. Quando, invece, N³ 3 è possibile introdurre un meccanismo a maggioranza (voting), introducendo un programma che svolge il compito di arbitro controllando i risultati prodotti dalle N versioni. Bisognerà definire nelle varie versioni dei punti nel quale le uscite devono essere controllate (checkpoint). La programmazione N-Version non può essere applicata quando sono possibili più output corretti e accettabili. Si pensi a un algoritmo che calcoli la soluzione di una equazione di ordine n, questo ha problema ha n differenti risposte corrette. Il meccanismo del recovery block [12,15] è stato originariamente introdotto da un gruppo di ricercatori dell’Università di Newcastle ed è simile all’approccio della ridondanza dinamica usato nell’hardware esposto nel paragrafo 2.2. Consiste in tre elementi software:
La struttura di un recovery block è: La clausola ensure specifica il test di accettazione, la clausola by indica la routine primaria e la clausola else by individua la routine alternativa da utilizzare se quella primaria fornisce dei risultati non corretti, si può inserire un numero arbitrario di clausole else by. La routine primaria può essere progettata in modo che sia la più veloce possibile, mentre la routine alternativa può essere più lenta (viene usata un minor numero di volte), implementata in modo semplice in modo da implementare correttamente le specifiche.
3. La tolleranza ai guasti nei sistemi operativi Ma un "normale" sistema operativo, come fa a gestire un errore? Sicuramente prima deve classificare l’errore con certezza, dopo di che deve gestirlo secondo alcune politiche specifiche. Di seguito vediamo come tre sistemi operativi gestiscono queste situazioni[17]. Prendiamo OS/2: quando capita un errore, esso viene classificato ed in base ad una tabella viene associata l’azione da intraprendere. Sotto possiamo vedere la tabella degli errori, della locazione degli stessi e quella della possibili azioni da intraprendere.
Ad esempio, un errore di Situazione Temporanea su una Rete, porterà all’azione: Aspetta e riprova. Errori come: l’utente che non inserisce completamente il dischetto, sono chiamati "hard errors" e questi non possono essere corretti dal sistema (il dischetto deve per forza essere inserito, prima che il sistema possa procedere). Il DOS essendo monotask gestisce questa classe di errori in modo semplice: sospende l’operazione, visualizza un messaggio, aspetta che l’utente agisca e poi prosegue. OS/2 essendo un ambiente multitask non può sospendere tutte le operazioni mentre aspetta una risposta da un processo o un thread. Prima deve determinare qual è la fonte dell’errore perché più processi possono avervi partecipato (in DOS questo è banale, perché esiste un solo processo). Inoltre OS/2 usa tecniche di bufferizzazione che portano ad un hard error, quando in quel momento nessun processo sta facendo operazioni di I/O. In OS/2 esiste quindi un processo che gira in background chiamato Hard Error Daemon, il cui compito è quello di monitorare questo tipo di errori. Quando accade un errore, il demone attiva un processo che visualizza il messaggio appropriato all’errore e attende input. Il processo responsabile si blocca in attesa della risposta dell’utente. Il demone inoltre rilancia la risposta al kernel il quale permette al thread di prendere la decisione appropriata. A questo punto il thread ritenta e se necessario genera un errore. Il tutto ricomincia da capo.
Il sistema operativo montato sui PC della famiglia Macintosh lavora in modo analogo. Esiste un Gestore di errori di sistema il quale risponde e gestisce gli errori fatali di sistema. Visualizza sul display una finestra che avvisa l’utente dell’errore e incomincia a prendere provvedimenti sull’applicazione che ha creato l’errore, cioè se riprendere il suo funzionamento oppure riavviarla. Un errore di sistema, di solito significa che il guasto è accaduto nel sistema operativo. Questo tipo di errori porta al non funzionamento di parti chiave del software Macintosh, così il Gestore è costruito in modo da far riferimento il meno possibile ad altre parti del Sistema Operativo, in particolare il Memory Manager. Il Gestore di errori classifica l’errore utilizzando una tabella simile a quelle viste per OS/2, così determina anche quale messaggio visualizzare. In Macintosh esistono due tipi di tabelle: quelle per gli errori in caso di startup del sistema e un’altra per il sistema già funzionante. L’applicazione che ha creato l’errore può recuperarsi tramite l’operazione di resume. Se l’utente clicca sul bottone Resume nella finestra di dialogo, il Gestore prima tenta di recuperare lo stato precedente del sistema e poi invoca la procedura di resume per l’applicazione. Come ultima nota, bisogna dire che il Gestore di errori è normalmente chiamato dal sistema operativo e non direttamente dall’applicazione; questa dovrà occuparsi del recupero e dell’operazione di resume. Nel sistema UNIX esiste la tabella dei segnali che analogamente agli interrupt informano in modo asincrono un processo di un evento capitato. A differenza degli interrupts, i segnali di Unix non hanno livello di priorità. I segnali possono essere mandati ad un processo da: hardware, kernel, altri processi, utente. In ogni caso non devono essere utilizzati come mezzo di comunicazione (per questo, esistono: pipes, messaggi, semafori, e socket).
In risposta ad un segnale, un processo può eseguire la cosiddetta azione di default (di solito terminandosi e informando il processo padre), ignorare il segnale, oppure fare un catch del segnale (in questo caso una particolare funzione di gestione del segnale viene invocata dopo il ricevimento del segnale stesso). É ovvio che solo alcuni di questi segnali sono utilizzati per il Fault Tolerance. L’ambiente del processo contiene le informazioni che specificano come un processo deve rispondere ad ogni segnale. Inoltre per un processo che sta eseguendo operazioni considerate critiche e non vuole essere interrotto, è possibile eseguire le chiamate sigblock e sigsetmask per ritardare i segnali in arrivo fino a che la sezione critica è completata.
4. La tolleranza ai guasti nelle basi di dati Nel mondo delle basi di dati è molto sentito il problema della tolleranza ai guasti ed in particolare si vuole un DBMS (Data Base Management System) in grado di garantire l’affidabilità dei dati memorizzati, cioè la capacità del sistema di conservare intatto il contenuto della base di dati (o almeno permettendone la ricostruzione) in caso di malfunzionamenti hardware e software. A questo scopo i DBMS forniscono specifiche funzionalità di salvataggio e ripristino (backup e recovery).
4.1 Definizione di transizione Una transazione identifica una unità elementare di lavoro svolta da un programma applicativo, cui si vogliono associare particolari caratteristiche di correttezza, robustezza e isolamento [13]. Un sistema che mette a disposizione un meccanismo per la definizione e l’esecuzione di transazioni viene detto sistema transazionale. Ogni transazione è incapsulata all’interno di due comandi: begin transaction (bot) ed end transaction (eot). All’interno del codice della transazione possono apparire due particolari istruzioni:
Es.: Transazione bancaria: trasferimento di 1000 dal conto X al conto Y
4.1.1 Proprietà acida delle transizioni Tutto il codice eseguito fra una coppia bot – eot gode di proprietà particolari, le cosiddette proprietà acide delle transazioni: atomicità, consistenza, isolamento e persistenza (il termine acide è in acronimo derivante dall’inglese, ove ACID denota le iniziali di: "Atomicity, Consistency, Isolation, Durability") [13]. Atomicità: rappresenta il fatto che una transazione è un’unità indivisibile di esecuzione, non è quindi possibile lasciare la base di dati in uno stato intermedio attraversato durante l’elaborazione della transazione. Se durante l’esecuzione di una transazione si verifica un errore il sistema deve essere in grado di ricostruire la situazione esistente all’inizio della transazione (operazione di undo). Consistenza: l’esecuzione della transazione non deve violare i vincoli di integrità definiti sulla base di dati. Isolamento: l’esecuzione della transazione deve essere indipendente dalla contemporanea esecuzione di altre transazioni. Persistenza: richiede che l’effetto di una transazione che ha eseguito il commit correttamente non venga più perso (operazione di redo).
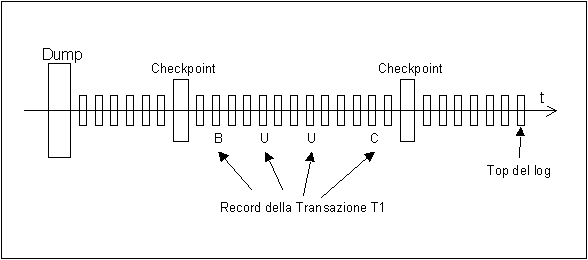
Il controllo di affidabilità garantisce le proprietà di atomicità e persistenza. Il gestore dell’affidabilità è responsabile della scrittura del log, un archivio persistente che registra le varie azioni svolte dal DBMS, il file di log permette di svolgere le operazioni di redo e undo, operazioni basilari per i meccanismi di ripristino dei guasti. Questo log è memorizzato in una memoria stabile resistente ai guasti. La memoria stabile è una astrazione (nessuna memoria può avere probabilità nulla di fallimento) sul quale si basano i meccanismi di controllo di affidabilità e che considerano i guasti nella memoria stabile come eventi catastrofici. 4.2.1 Organizzazione del log Sul log vengono registrate le azioni svolte dalle varie transazioni (si veda la figura riportata sotto per un esempio), i record del log possono essere di due tipi: di transazione e di sistema.
Record di transazione:
Record di sistema
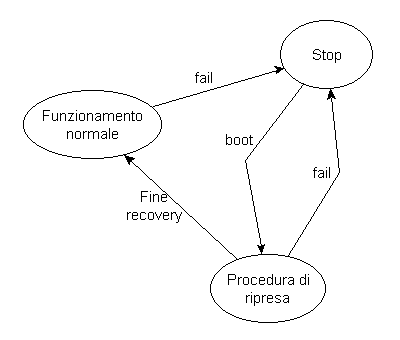
Il modello ideale (si veda la figura riportata sotto) in cui ci poniamo è detto di fail-stop: quando il sistema individua un guasto viene forzato un arresto completo delle transazioni e il successivo ripristino del corretto funzionamento del sistema operativo (boot). Quindi, viene eseguita la procedura di ripresa (a caldo o a freddo), rendendo così il sistema nuovamente utilizzabile dalle transazioni.
4.2.2 Meccanismo di ripresa a caldo (warm restart) Si attua quando si perde la memoria centrale, mentre è intatto il contenuto della memoria di massa (per esempio quando cade la corrente). Il meccanismo di ripresa a caldo è articolato in quattro fasi [13]:
4.2.3 Meccanismo di ripresa a freddo (cold restart) Si attua quando si perde una parte della memoria di massa (per esempio strisciamento delle testine di un disco). Il meccanismo di ripresa a caldo è articolato in tre fasi [13]:
5. La tolleranza ai guasti nelle reti Nelle reti di telecomunicazioni, il controllo e la correzione di errore, può essere fatta teoricamente ad ogni livello della pila ISO/OSI. In pratica la correzione dell’errore viene effettuata mediante ritrasmissione del dato (pacchetto di dati) errato, ricevuto incompleto oppure mai arrivato a destinazione. Infatti i protocolli di correzione di errore si definiscono in terminologia retaiola come ARQ (Automatic Repeat reQuest). Inoltre lo sviluppo della tecnologia ha portato ad un primo livello (fisico) che presenta tassi di errore molto bassi, questo porta ad alzare di livello il controllo di errore, cercando di lasciare "più leggeri" i livelli bassi della pila. Quindi, anche se storicamente il controllo di errore si è sempre localizzato a livello 2, oggi si tende ad eliminarlo da questo livello per non appesantire i protocolli. Inoltre si è avuta storicamente un graduale passaggio da protocolli orientati al byte, a protocolli orientati al bit, perché i primi portano ad avere un overhead maggiore e più difficoltà nel riconoscimento di errori. Esaminiamo quindi 3 tipologie di ARQ.
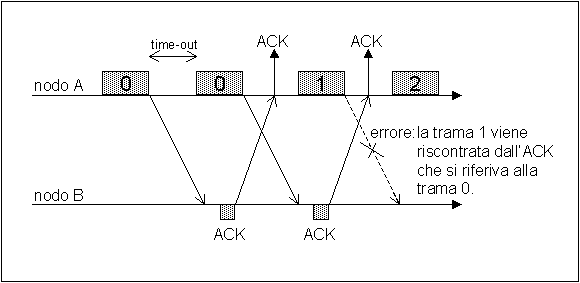
5.1 Stop and Wait É il più semplice protocollo pensabile. Il trasmettitore dopo l’invio di una trama aspetta un riscontro positivo (ACK) dal ricevitore. Se non lo riceve dopo un prefissato intervallo di tempo (time-out) la trama viene inviata di nuovo. In alternativa il ricevitore può inviare un NAK (riscontro negativo) se il CRC indica una trama errata. In ogni caso però, il corretto funzionamento non può essere garantito dal solo uso del NAK perché una perdita di questo, porterebbe all’impossibilità di rilevare l’errore da parte del trasmettitore. Per evitare inutili ripetizioni, si può numerare i pacchetti inviati in modulo 2 (Sending Number SN=0, 1). Questa numerazione dovrà trovare posto nell’header aggiunto dal protocollo.
Dualmente, a causa di ritardi o malfunzionamenti la stazione trasmittente può non essere in grado di riconoscere a quale trama l’ACK si riferisce. Occorre dunque che anche il riscontro porti il numero della trama a cui esso si riferisce. Ciò rende non più necessario l’uso del NAK. Tuttavia è pratica inviare, non il numero della trama ricevuta, ma quello dello prossima trama attesa, indicato come RN (Request Number) [3].
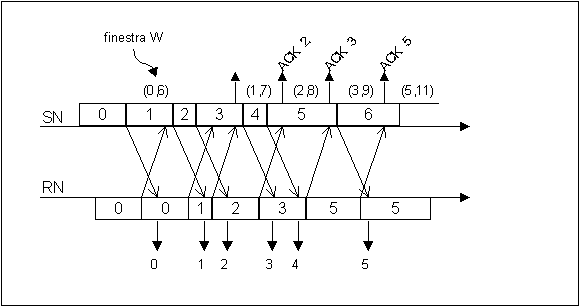
5.2 Go back n Per risolvere gli inconvenienti del protocollo precedente in caso di tempi di propagazione molto grandi (e quindi lunghe attese), questo protocollo permette la trasmissione successiva di un certo numero di pacchetti consecutivi a partire dall’ultimo riscontrato senza errore. Poiché questa variante rende i ritardi di riscontro meno critici, si ha la possibilità di funzionamento full-duplex. Così i messaggi di servizio vengono accodati insieme ai pacchetti dati; in alternativa si può utilizzare il piggy-backing, che consente di trasmettere gli ACK inserendoli nell’header di pacchetti destinati alla controparte. In pratica il protocollo opera numerando i pacchetti da trasmettere con un campo SN (nell’header), mentre il riscontro viene effettuato con un campo RN (sempre nell’header), che indica il numero della trama che il ricevitore si aspetta ed agisce come ACK per tutti i pacchetti con SN<RN.
In pratica quando un pacchetto non è ricevuto correttamente, il ricevitore continua a rimandare lo stesso RN e scarta tutti i pacchetti finché il trasmettitore se ne accorge e manda quello con SN=RN.
5.3 Selective reject Questo protocollo è identico al precedente, ma il ricevitore conserva in un buffer tutti i pacchetti corretti, ma fuori sequenza perché uno precedente era errato. In questo caso si evita quindi la ritrasmissione di pacchetti, anche se bisogna informare il trasmettitore del pacchetto (o dei pacchetti) che mancano e di quelli arrivati correttamente. Questo protocollo porta ad un overhead maggiore, alla necessità di introdurre dei buffer, anche se tutto è bilanciato dal tempo che si risparmia in ritrasmissioni.
Come già ricordato, essi sono quasi tutti di livello 2 nella pila ISO/OSI, perché questa è la collocazione classica del controllo di errore nelle reti di telecomunicazioni [3].
|