|
|
|
|
Concetti generali sulla tolleranza ai guasti
Il primo a fornire una precisa definizione di sistemi tolleranti ai guasti fu A. Avizienis nel 1967, affermando che un sistema è detto Fault Tolerant se i suoi programmi possono essere eseguiti in modo corretto nonostante l’occorrenza di guasti fisici. Questa definizione fu il risultato di tre principali filoni di studio convergenti tra loro. Innanzitutto l’utilizzo dei primi calcolatori rese evidente il fatto che, nonostante un attento sviluppo del sistema e l’utilizzo di componenti di buona qualità, i difetti fisici e gli errori di progetto erano inevitabili. Così i progettisti dei primi calcolatori iniziarono ad utilizzare tecniche pratiche per aumentare l’affidabilità:
In parallelo all’evoluzione di queste tecniche alcuni pionieri dell’informatica, come John Von Neumann, Edward Moore e Claude Shannon, affrontarono il problema di costruire un sistema affidabile a partire da componenti che non lo erano. La NASA diede un gran contributo quando nel 1958, al Jet Propulsion Laboratory (JPL) iniziò a studiare come costruire astronavi prive di equipaggio per l’esplorazione interplanetaria. Per queste missioni si dovevano realizzare dei calcolatori in grado di resistere ad un viaggio di parecchi anni e che continuassero a fornire alte prestazioni nella profondità dell’universo. JPL e IEEE nel 1971 realizzarono la prima conferenza sul calcolo con tolleranza ai guasti.
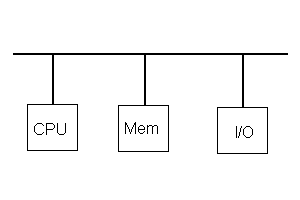
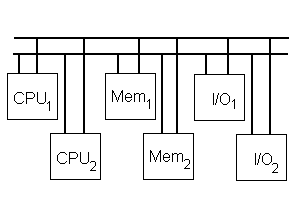
La ridondanza è la chiave che permette di ottenere un sistema tollerante ai guasti. La ridondanza è definita come quella parte del sistema che non è necessaria per il corretto funzionamento del sistema, se la tolleranza ai guasti non è supportata. Così un sistema funziona correttamente senza ridondanza se non è presente nessun malfunzionamento. La ridondanza può essere nell’hardware (vedi figura), nel software o temporale (esecuzioni ripetute nel tempo dello stesso algoritmo).
Due importanti funzioni di cui bisogna tenere conto nella fase di design di un sistema, sono la disponibilità e l’affidabilità. La disponibilità è in funzione del tempo, e rappresenta la probabilità che il sistema sia operativo correttamente ad un certo tempo t. Se si manda t a infinito, il limite rappresenta la frazione di tempo cui il sistema è utilizzabile efficacemente. Di solito questa funzione dà un valore di merito ad un sistema. L’affidabilità è anch’essa in funzione del tempo e rappresenta la probabilità che il sistema sia correttamente funzionante all’istante t, condizionata dal fatto che era funzionante al tempo 0. Questa funzione è utilizzata soprattutto per sistemi dove le riparazioni sono difficoltose o impossibili (ad esempio un satellite), oppure per sistemi critici, dove il tempo di riparazione non può essere lungo più di tanto (ad esempio un sistema di controllo di un aereo). In generale, l’affidabilità dà requisiti più stringenti della disponibilità. Una dimensione che non bisogna tralasciare, e che in alcuni casi fa propendere per una soluzione o per un’altra, è il costo, che non è semplicemente il costo di acquisto del sistema, ma anche tutti i costi aggiuntivi per mantenere il sistema stesso in piena efficienza. Quindi si avranno i seguenti costi: acquisto, preparazione dell’ambiente fisico, manutenzione, materiali di consumo, ammortamento.
I guasti si possono ripartire secondo due classificazioni [18,11].Avaria o insuccesso (failure): un cambiamento fisico dell’hardware Guasto (error): uno stato erroneo dell’hardware o del software, derivante da avaria, interferenze dall’ambiente, errori di design, errori umani. Errore (fault): la manifestazione di un guasto all’interno di un programma o di una struttura dati.
Permanente: un guasto continuo e stabile. Nell’hardware è un irreversibile cambiamento fisico. Intermittente: un guasto o errore che si presenta occasionalmente e in modo instabile, varia al variare degli stati del software e dell’hardware. Transiente: guasto o errore che è il risultato di particolari e temporanee condizioni ambientali.
Un guasto può essere causato da un’avaria fisica, una inadeguatezza nel design del sistema, da un’influenza dell’ambiente o da un operatore. Un’avaria permanente porta ad un guasto permanente. Guasti intermittenti possono essere causati da un instabile, marginalmente stabile o incorretto design. Particolari condizioni ambientali portano a guasti transienti. Tutti questi guasti portano ad errori. Gli errori possono essere causati direttamente da errori umani o da design incorretto.
I guasti risultanti da condizioni fisiche dell’hardware, incorretto design dell’hardware o del software, o da ripetitive condizioni ambientali sono tutti potenzialmente riconoscibili e riparabili con sostituzioni o con un redesign. I guasti dovuti a temporanee condizioni ambientali (come scariche elettriche, accoppiamenti elettromagnetici, forti variazioni termiche, raggi cosmici, particelle alfa), sono tuttavia irreparabili, perché l’hardware non è danneggiato a livello fisico. Quindi, anche in assenza di difetti fisici, errori possono essere causati proprio da guasti transienti, che rappresentano assieme ai guasti intermittenti, la maggior causa di errori in un sistema. Inoltre i guasti transienti sono difficili da localizzare (lo stesso dicasi per la loro causa) sia a livello hardware che a livello software (molte informazioni sono perse dal sistema operativo e non è sempre possibile ritrovare tutta la registrazione delle condizioni al momento del guasto, ad esempio il processore che riporta una eccezione NXM (nonexistent memory) e da successive analisi, risulta tutto a posto; oppure problemi di clock sospettati, dove però mancano informazioni aggiuntive per trovare il guasto).
A seconda del livello di astrazione cui ci poniamo, i guasti possono essere:
Correttezza (correctness) significa avere un sistema che non contenga guasti ed errori nei suoi dati interni. Affidabilità (reliability) non significa avere un sistema privo di errore e guasti, ma che sia in grado di tollerarli. L’architettura di un sistema operativo affidabile deve fornire questi quattro meccanismi [16]:
L’ordine in cui le fasi (analizzate nei paragrafi successivi) sono intraprese può variare da sistema a sistema. La rilevazione degli errori è il punto di partenza usuale della tolleranza ai guasti, mentre le altre tre fasi possono trovarsi in un qualsiasi ordine, sebbene succeda spesso che la valutazione del danno preceda la copertura degli errori e il trattamento dei guasti. Comunque un progettista di un sistema fault tolerant dovrà prima di tutto valutare dove la tolleranza ai guasti è davvero richiesta e valutare quanto sia essa necessaria. Si sono sviluppate nel tempo due differenti metodologie:
Lo scopo di questa fase è quello di sollevare delle eccezioni a fronte delle quali le successive fasi della Fault Tolerance provvederanno ad eseguire le dovute azioni di recupero. Volendo tollerare un guasto di un sistema, deve essere rilevato, innanzitutto, il suo effetto, cioè andando a rilevare uno stato erroneo. Il successo di un sistema tollerante ai guasti sarà, quindi, dipendente dall’efficacia delle tecniche per la rilevazione degli errori utilizzate. In sostanza, più rilevazione di errori viene utilizzata in un sistema, più si avranno benefici per l’affidabilità delle operazioni in esso eseguite. Nella pratica, però, ci sano limitazioni sul numero di errori rilevabili: ovvie limitazioni saranno i costi per attuare le ridondanze necessarie per la rilevazione degli errori e l'appesantimento in fase di esecuzione dovuto alle continue verifiche della consistenza delle variabili e dei contesti che si stanno eseguendo. Un approccio ideale alla rilevazione degli errori è quello di considerare un sistema S progettato per fornire un determinato servizio, se il comportamento di S non segue quello prescritto dalle sue specifiche, allora S si trova in uno stato erroneo. Poiché lo scopo della tolleranza ai guasti è quello di prevenire i guasti ne consegue che adeguate misure per la rilevazione degli errori possono essere basate nell’intercettare i valori di uscita di S e di verificare se tali valori sono o no conformi alle specifiche. Di fatto, ci si trova di fronte ad un nuovo sistema S’ composta da S e da componenti aggiuntivi aventi lo scopo di compiere la verifica [15].
Per verificare se i valori di uscita di S rispettano le specifiche sarà necessario fornire un’implementazione alternativa che modelli il servizio richiesto e attraverso cui possa essere comparata l’attività di S. Il successo della verifica dipenderà dalla correttezza e dall’accuratezza del modello. Nella pratica, per la maggior parte dei sistemi non è possibile applicare un controllo così rigoroso, e quindi viene realizzato un controllo sull’accettabilità dei valori di uscita. L’accettabilità è uno standard più basso di comportamento rispetto all’assoluta correttezza, senza garanzie di assenza di errori, il suo scopo è quello di rilevare la maggior parte delle situazioni erronee ed aumentare la fiducia nelle operazioni del sistema.
Quando l’errore viene rilevato, si può sospettare che la maggior parte del sistema ne sia stato influenzato, e si trovi, ora, in uno stato erroneo. A causa del tempo intercorso tra la manifestazione del guasto e la rilevazione delle sue conseguenze erronee, potrebbe essersi diffuse nel sistema informazioni non consistenti, portando, così, ad ulteriori errori non ancora rilevati. Prima che venga fatto qualsiasi tentativo di copertura sarà quindi necessario valutare l’estensione del danno nel sistema.
Queste tecniche hanno lo scopo di trasformare lo stato erroneo di un sistema in uno ben definito e libero da errori da cui si possa far ricominciare la computazione. Senza questa fase il guasto continuerà ad essere presente e ad influenzare sempre più il sistema, dunque la copertura dell’errore è uno dei più importanti aspetti della tolleranza ai guasti ed è una delle aree di studio maggiormente affrontate. Un segnale di errore scatena un a procedura che tenterà di riportare il sistema in uno stato consistente. Questo può avvenire in due modi:
Quando si identifica un sottosistema permanentemente guasto, viene eseguita la rimozione del guasto o sostituendo il sottosistema con una riserva funzionante o riconfigurando il sistema in modo che funzioni senza il sottosistema guasto. Due speciali casi di copertura sono:
Nonostante la fase di copertura dei guasti possa riportare il sistema ad uno stato senza errori, può rendersi necessario trovare tecniche che permettano al sistema di continuare a fornire il servizio richiesto con le sue caratteristiche, assicurandosi che quel guasto, di cui gli effetti sono stati coperti, non ricorra nuovamente. Un problema nel trattamento dei guasti è che la rilevazione di un errore non necessariamente è utile alla identificazione del guasto. La relazione fra gli errori e i guasti può essere complessa: persino in sistemi semplici può accadere che più di una tipologia di guasti provochi lo stesso errore. Il primo aspetto del trattamento dei guasti sarà quello di cercare di collocare adeguatamente il guasto. In questo modo, possono essere intrapresi i passi per la sua riparazione o per la riconfigurazione del resto del sistema per impedire un nuova ricorrenza; in alternativa, nessuna azione sarà necessaria se il guasto è stato interpretato come transitorio.
|