Capitolo 4: Alcuni Sistemi Operativi Real-Time Distribuiti
4.4 IL SISTEMA OPERATIVO REAL TIME QNX
4.5 IL SISTEMA OPERATIVO REAL-TIME CHORUS
4.1 ARTS
ARTS è un sistema operativo real-time distribuito sviluppato nel progetto ART (Advanced Real-time Technology) Lo scopo di ARTS è di fornire agli utenti un ambiente di computazione real-time distribuito predicibile, analizzabile ed affidabile, in modo tale che un progettista di sistema possa analizzare il sistema nella fase di progetto e predire se i task real-time con vari tipi di interazioni fra loro possano soddisfare i loro requisiti temporali. Gli aspetti originali di ARTS sono il suo focus sulle applicazioni real-time distribuite, il suo supporto integrato di tools di monitoraggio usati per la valutazione temporale e infine il suo supporto di protocolli di comunicazione real-time sulla trasmissione video dal vivo. Le ultime versioni di ARTS hanno fatto da precursore al sistema RT-Mach, che vedremo poi. In queste versioni, la rappresentazione originale task-based dei programmi paralleli e distribuiti è rimpiazzata da una che usa threads real-time con un modello ad oggetti posto in cima ai threads. Associata con l'invocazione degli oggetti c'è un'analisi di schedulabilità, in cui ogni operazione di un oggetto ha un associato tempo di esecuzione nel caso peggiore, chiamato valore di 'time fence' e una routine di gestione delle eccezioni temporali. Quando l'operazione è invocata da un thread real-time, essa viene eseguita se c'è sufficiente tempo di computazione rimanente allocato al thread chiamante per completare l'operazione. Altrimenti, l'invocazione è abortita e viene sollevata un'eccezione. Gli oggetti sono implementati usando il linguaggio C o C++ con estensioni real-time, chiamato RTC++.
Scheduling. Il kernel ARTS implementa un Integrated Time Driven Scheduler (ITDS). Lo scheduler ITDS fornisce un'interfaccia tra le politiche di scheduling e il resto del sistema operativo. L'approccio object oriented viene usato anche per implementare lo scheduler, con le politiche di scheduling incorporate nell'oggetto scheduler. Ogni istanza dello scheduler può avere una diversa politica di scheduling che governa il comportamento dell'oggetto, con solo una istanza attiva in un dato istante.
Real-Time Threads. Sottostanti gli oggetti ARTS vi sono i threads real-time. Ogni thread ha un nome di procedura associato e un descrittore di stack che specifica la dimensione e l'indirizzo dello stack del thread. Un thread real-time può essere hard o soft. Un thread real-time hard deve completare le sue attività entro la sua deadline mentre le deadline dei threads real-time soft sono meno importanti. Un thread real-time può essere definito come periodico o aperiodico a seconda della natura delle sue attività. I threads real-time in ARTS usano metodi di scheduling priority based.
Sincronizzazione. ARTS fornisce primitive di Lock e Unlock per delimitare le regioni critiche. Quando un thread vuole lockare una variabile già lockata, viene accodato in una coda di thread. Se la priorità del thread chiamante è maggiore della priorità del thread che si trova nella regione critica, la priorità del thread nella sezione critica viene aumentata a quella del thread chiamante, in tal modo prevenendo l'inversione di priorità. Quando il thread lascia la regione critica, viene ristabilita la sua priorità originaria.
Communication Scheduling. Nel progetto ARTS, viene usato un paradigma di scheduling rate monotonic esteso. Questo permette al sistema di integrare lo scheduling del messaggio e del processore con una uniforme politica di gestione della priorità. E' stato sviluppato un modello algoritmico di scheduling per una rete Token Ring IEEE 802.5 e poi proposta una modifica all'algoritmo di controllo del chip-set adattatore del token ring.
ARTS implementa una struttura di comunicazione usata come banco di prova per nuovi algoritmi e protocolli di comunicazione ed anche per nuovo hardware real-time.
Infatti protocolli come VMTP sono stati implementati con successo nel kernel ARTS.
Inoltre, è stato sviluppato un Real-time Transfer Protocol (RTP) per esplorare diverse questioni nella comunicazione real-time. RTP mette in evidenza i messaggi prioritizzati e un meccanismo time fence.
L'RTP manager implementa il protocollo RTP e così forma un singolo punto attraverso il quale devono passare le comunicazioni remote.
Un altro protocollo usato è il Capacity-Based Session Reservation Protocol (CBSRP), poi esteso per realizzare comunicazioni real-time predicibili e valutato in ARTS su una Fiber Distribution Data Interface (FDDI).
Infatti alcuni dei contributi più interessanti di ARTS sono i risultati riguardanti il display dell'informazione di scheduling e la ricerca sui protocolli di comunicazione multi-media usando link FDDI.
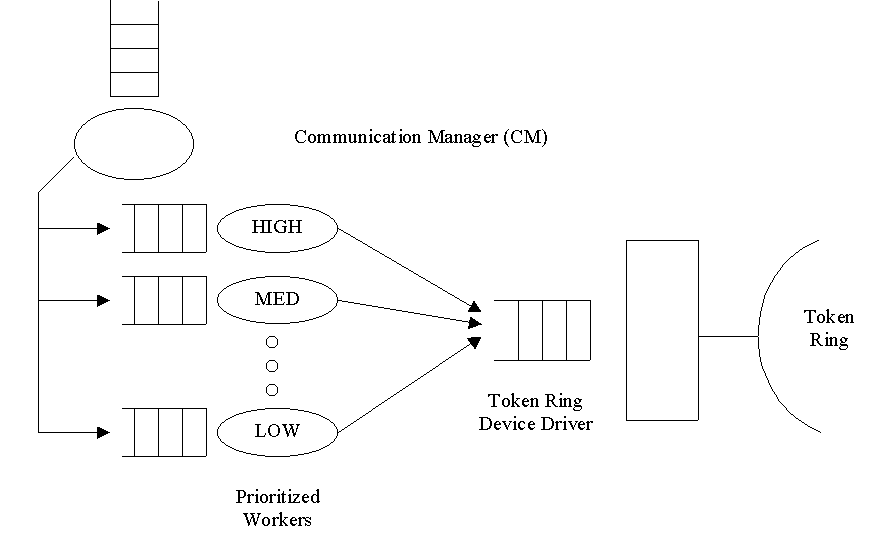
Figura 4.1. La struttura del sottosistema di comunicazione ARTS
Il focus principale del progetto Maruti è di esaminare i costrutti di sistemi operativi distribuiti, hard real-time e fault tolerant. Maruti è un sistema object-based, con incapsulamento di servizi. L'oggetto consiste di due parti principali: una parte di controllo (o joint) che è una struttura dati ausiliaria associata ad ogni oggetto, e un insieme di punti di accesso al servizio (SAPs) che sono punti di entrata ai servizi offerti da un oggetto. Ogni joint mantiene l'informazione dell'oggetto (come il tempo di computazione, l'informazione di protezione e sicurezza) e i requisiti (come i requisiti di servizi e di risorse). L'informazione temporale, mantenuta nell'oggetto, è dinamica ed include le relazioni temporali tra gli oggetti. Un calendario, una struttura dati ordinata dal tempo, contiene il nome dei servizi che saranno eseguiti e l'informazione temporale per ogni esecuzione.
In Maruti, ogni applicazione è descritta in termini di un grafo di computazione, che è un grafo aciclico diretto con radice. I vertici rappresentano i servizi e gli archi descrivono le precedenze temporali e di dati tra due servizi. Gli oggetti comunicano l'uno con l'altro attraverso link semantici. Tali link realizzano il controllo di range e di tipo dell'informazione. Gli oggetti che risiedono in siti differenti hanno bisogno di agenti come rappresentativi sui siti remoti.
Maruti è organizzato su tre livelli distinti: il kernel, il supervisore e il livello applicativo. Il kernel è il minimo insieme di server necessari a tempo di esecuzione. Consiste di un insieme di oggetti core-resident che includono:
Gli oggetti supervisori in Maruti preparano tutte le computazioni future, assicurando la loro esecuzione temporalmente corretta con la preallocazione di risorse, ove possibile. Gli oggetti del livello supervisore in Maruti sono:
L'implementazione iniziale di Maruti fu su una rete di workstations SUN Unix, seguita dall'implementazione del kernel su Stazioni Dec.
Real-Time Mach (RT Mach) si occupa in modo principale degli aspetti real-time dei threads, della sincronizzazione dei threads, della interprocess communication (IPC), e di qualche altro meccanismo che consenta di raggiungere una maggiore predicibilità.
In più, il progetto RT Mach ha sviluppato un tool-set per il progetto e l'analisi di programmi real-time.
Dell'altro lavoro è stato fatto sulle estensioni per applicazioni multimediali.
Real-Time Threads. Come in altri sistemi operativi RT Mach accresce il modello dei threads con attributi temporali. Usando una definizione standard di un thread periodico (un thread appena istanziato deve essere schedulato ad intervalli determinati dal suo periodo), la definizione di un thread aperiodico in RT Mach include un tempo di inter-arrivo del caso peggiore dopo il quale il thread aperiodico ricorre. Inoltre, sia i thread periodici che quelli aperiodici possono avere deadline hard o soft, dove un thread soft-deadline ha un abort time usato dallo scheduler per determinare quando abortire il thread.
In aggiunta, l'importanza semantica di un thread è specificata attraverso una value function associata al thread. Ci sono primitive per creare, terminare, uccidere e sospendere un thread oltre a quelle per acquisire e settare gli attributi di un thread.
Threads Scheduling. RT Mach usa il Integrated Time-Driven Scheduler (ITDS) originariamente sviluppato per ARTS e poi esteso per RT Mach stesso. Mach fornisce a insiemi di processori (che sono collezioni di processori disponibili per un'applicazione) code di esecuzione specifiche dell'insieme di processori. Lo scheduler ITDS estende questo approccio permettendo cinque politiche differenti (Rate Monotonic, Fixed Priority, Round Robin con Server Differibile, e Round Robin con Server Sporadico) su ogni insieme di processori in RT Mach, con primitive per acquisire e settare la politica di scheduling. Lo scheduler ITDS utilizza uno schema di capacity preservation, con cui i cicli di processore disponibili sono prima assegnati ai job hard periodici e aperiodici, e ciò che rimane è quindi assegnato ai job soft real-time secondo le rispettive value functions.
Sincronizzazione. Gli algoritmi di RT Mach per la sincronizzazione real-time determinano gli ordini di coda per il mutex lock e le primitive di condizione offerte per la sincronizzazione nei threads real-time, con lo scopo di alleviare i problemi di blocco che si sa esistono nella sincronizzazione real-time.
Inoltre, RT Mach permette politiche di sincronizzazione diverse da usare con istanze diverse di lock e condizioni. Di conseguenza, un thread può essere o non-preemptable (la preemption non è permessa quando il thread è in una regione critica), o preemptable (un thread a più alta priorità può interrompere il thread correntemente in esecuzione, ma il primo deve bloccarsi se vuole accedere ad una regione critica che è in uso dal secondo), oppure restartable (un thread a più alta priorità può interromperne uno correntemente in esecuzione; se il primo desidera entrare in una sezione critica in uso dal secondo, lo fa; il thread interrotto a più bassa priorità ricomincia più tardi dall'inizio della sezione critica).
Scegliendo appropriati schemi di ordinamento della coda con uno degli schemi di preemption ammissibili, possono essere supportate cinque politiche di sincronizzazione:
Real-time communications. Le estensioni IPC in RT Mach derivano dai risultati sulla sincronizzazione visti sopra. Specificamente, è chiaro che messaggi in coda in ordine FIFO, accettabili per applicazioni non real-time, possono causare ritardi non delimitati nel ricevere messaggi ad alta priorità. Questo problema viene affrontato usando code priority-based nei buffer dei messaggi. Inoltre, devono esistere primitive per propagare le priorità dal mittente di un messaggio al destinatario, e ci devono essere meccanismi per ereditare le priorità dal mittente al destinatario di un messaggio (altrimenti il processing di un messaggio o la ricezione di un messaggio da un server potrebbe essere interrotta o ritardata). Oltre a ciò, visto che ci possono essere riceventi multipli in un singolo server, bisogna prendere una decisione su quale thread ricevente debba processare un messaggio in ingresso.
Per gestire i messaggi real-time, devono essere definiti per le porte dei messaggi quattro attributi:
Considerazioni finali su RT Mach. Un secondo sforzo per migliorare Mach per applicazioni real-time e multimediali utilizza threads deadline-driven e threads event-driven. I primi vengono usati per dispositivi in cui il media non si deteriora se le operazioni sul dispositivo stesso sono completate prima di una deadline. I secondi sono usati per quei dispositivi in cui l'operazione deve essere iniziata immediatamente dopo che un evento occorra. Tali dispositivi possono anche avere deadline esplicite, dove la risposta del dispositivo si deteriora all'aumentare del tempo di risposta del software.
La caratterizzazione dei thread real-time include un tempo di start, una deadline, un tempo di esecuzione nel caso peggiore, ed un 'peso' che specifica l'importanza relativa del thread. Le notificazioni di eventi sono simili alla gestione di livello utente di un dispositivo: all'interrupt, un gestore esegue una piccola routine in modalità kernel sul dispositivo, viene assegnato un trap di sistema asincrono, viene invocato lo scheduler preemptive-deadline, e quindi le operazioni di livello utente proseguono.
E' stato anche sviluppato un temporal paging system (TPS) che permette un accesso real-time a grandi segmenti di dati, come è spesso richiesto nelle applicazioni multimediali. Ciò è necessario perché i page faults introducono problemi di predicibilità, se regioni di spazio di indirizzamento non vengono lockate in pagine core-resident. Ad esempio Unix permette di fare ciò in modalità superuser, così come la primitiva di Mach vm_wire permette questo locking delle pagine.
TPS fornisce una serie di meccanismi usati dai dispositivi che richiedono grandi spazi di indirizzamento. Inoltre, mentre la memoria convenzionale è indirizzata usando soltanto una coordinata spaziale (l'indirizzo), la memoria temporale è indirizzata usando indirizzi spaziali e temporali (quest'ultima deve essere all'interno di un range noto). Il contenuto della memoria temporale può cambiare quando la coordinata temporale è valida. Dopo questo periodo di tempo, il contenuto originario viene o rimosso dallo spazio di memoria o diviene memoria 'ordinaria', a seconda di un attributo che specifica la memoria temporale.
In più, la stessa pagina fisica può essere condivisa da più pagine temporali, se queste pagine non vengono usate nello stesso intervallo temporale, riducendo in tal modo l'utilizzo totale della memoria. L'implementazione TPS interagisce con il kernel del sistema operativo fornendogli dei consigli su quali pagine dovrebbero essere precaricate o swappate in ogni istante. Infine TPS fornisce un'interfaccia uniforme per l'accesso real-time alla memoria mappata a dispositivi specifici, dal momento che lascia al kernel di caricare o scaricare pagine, e il programmatore applicativo non deve conoscere le idiosincrasie hardware e/o relative alla latenza dello specifico dispositivo.
4.4 IL SISTEMA OPERATIVO REAL TIME QNX
Descrizione del sistema operativo. Il sistema operativo QNX è progettato per gestire personal computer di fascia medio bassa (basati su Intel x86, Pentium) collegati in rete locale, presenta caratteristiche Real-time, fornisce multitasking, possibilità di scheduling preemptive a priorità e veloci cambi di contesto.
Il sistema è altamente scalabile poiché può partire dal solo kernel con pochi moduli, per gestire applicazioni specifiche, fino alla gestione di sistemi per reti di macchine con centinaia d'utenti.
QNX basa le sue prestazioni su due principi: architettura del microkernel e comunicazione interprocesso (IPC) basata sullo scambio di messaggi con primitive bloccanti.
Il sistema operativo è composto da un microkernel, che si occupa solo delle funzioni di scheduling dei processi e gestione del passaggio di messaggi tra i vari processi, da processi detti di sistema, che si occupano di tutte le altre funzioni, e da processi standard tra cui vi sono i processi utente.
Una configurazione tipica prevede, oltre al kernel, processi di sistema quali:
Process Manager (Proc)
Filesystem Manager (Fsys, Efsys per sistemi embedded)
Device Manager (Dev)
Network Manager (Net)

Figura 4.2. Schema del sistema operativo QNX.
I driver per periferiche possono entrare a fare parte dei processi di sistema, diventando quindi trasparenti all'utente o restare processi standard conservando la propria identità verso gli altri processi utente. La comunicazione tra i processi è realizzata tramite passaggio di messaggi tra i processi con primitive di send, receive e reply, gestite dal kernel in modo altamente affidabile e quindi permette la gestione di processi Real-time, sia di tipo hard che soft, a patto di strutturare correttamente la cooperazione tra i vari processi. Visto che la comunicazione tra i processi è alla base delle funzionalità del sistema operativo QNX risulta semplice vedere le risorse di un'intera rete di nodi QNX come locali. Vari nodi, infatti, si differenziano per un identificatore, unico per ogni nodo, che permette al sistema operativo (e quindi anche all utente) l'identificazione univoca ed un utilizzo ottimale di tutte le risorse presenti.
Ambiente applicativo e specifiche Real-time. QNX si adatta a sistemi medi di calcolatori collegati in rete locale dove siamo presenti applicazioni con specifiche Real-time, sia soft (mission critical) che hard (deadline non oltrepassabili), quali sistemi di controllo di processo distribuiti su reti locali.
Il sistema operativo cerca di minimizzare il tempo di risposta agli eventi esterni e massimizzare l'utilizzo della CPU. Le interruzioni, lasciate abilitate per la maggior parte del tempo, sono disabilitate solo per brevi sezioni critiche. Il massimo tempo in cui restano disabilitate è definito come latenza delle interruzioni e, nel caso peggiore, ha un valore di 3.3 microsecondi (usando un Pentium a 166 Mhz). La latenza di schedulazione, ossia il tempo necessario a mandare in esecuzione la prima istruzione del processo che gestisce l'evento associato all'interruzione, è di 4.7 microsecondi. Per operare un cambio di contesto sono necessari solo 2 microsecondi. Le latenze sono rese minime grazie alla presenza di un microkernel di dimensioni ridotte che opera frequenti e veloci cambi di contesto tra i processi.
Hardware e dimensioni del kernel. Il sistema QNX è usato su piattaforme dotate di processori 80x86, Pentium. L'intero sistema operativo può essere montato utilizzando poca memoria, il microkernel occupa uno spazio di 12 Kbytes ed unendo i processi di sistema si raggiungono 135 Kbytes. Per applicazioni embedded si può utilizzare un filesystem manager ridotto (Efsys) che occupa solo 60 Kbytes.
Il microkernel si occupa delle seguenti attività, che saranno poi discusse:
1) Gestione della comunicazione tra i processi (IPC)
2) Comunicazioni di rete a basso livello (tra nodo e nodo)
3) Schedulazione dei processi
4) Primo livello di gestione delle interruzioni (riceve le interruzioni hardware e lancia le subroutine di gestione a livello software)
Di seguito sono riportati alcuni dispositivi Hardware che il sistema supporta:
Processori
•AMD ÉlanSC300/310/400/410 •Am386 DE/SE •Cyrix MediaGX •Intel386 EX •Intel486 •ULP Intel486 •Pentium (with/without MMX) •Pentium Pro •Pentium II •STPC from STMicroelectronics •All generic x86-based processors (386 and up)
Bus
•CompactPCI •EISA •ISA •MPE (RadiSys) •STD •STD 32 •PC/104 •PC/104-Plus •PCI •PCMCIA •VESA •VME
Dispositivi Block-oriented
•Adaptec & BusLogic SCSI 1540/2 compatibles •Adaptec SCSI 6260, 6360, 6370 (ISA) •Adaptec SCSI 7770 (EISA & VESA), 7870/80 (PCI) •AMD SCSI 53C974 (PCI), 79C974 (Ethernet/SCSI for PCI) •ATAPI CD-ROMs •IDE/EIDE drives •NCR SCSI 53C810/815/820/825 (PCI) •PS/2 SCSI (MCA) •SCSI devices •360K/720K/1.2M/1.4M/2.8M floppies
Dispositivi Character-based
•Full ANSI, monochrome, and VGA •Pseudo-ttys •PC parallel 8255 and compatibles •PC serial 8250A, 8250B, 16540, and 16550
Hardware di rete
•3Com 10Mbit EtherLink II, EtherLink III (ISA) •AMD 10Mbit Ethernet 79C960, 79C961 & NE2100 (ISA), 79C965 (VESA), 79C970 (PCI), 79C974 (Ethernet/SCSI for PCI) •Crystal Semiconductor 10Mbit Ethernet CS8900 (ISA) •Digital 10/100Mbit Ethernet 21040, 21041, 21140 (e.g. SMC EtherPower), and 21142 (PCI) •Digital 100Mbit FDDI (EISA & PCI) •IBM & TROPIC-based 16/4Mbit Token Ring (ISA & MCA) •Novell NE1000 & NE2000 10Mbit Ethernet (ISA) •SMC 10Mbit Ethernet 91C90, 91C92 (ISA) •SMC Arcnet 9026, 9065, 9066 (ISA) •SMC Arcnet COM20020 (ISA) •WD/SMC 10Mbit Ethernet 8003, 8013, Elite, Ultra, EtherEZ (ISA & MCA) •Xircom Pocket Arcnet Adapter II
Dispositivi PCMCIA
•Cirrus Logic CL-PD6710/20/22/29/30 •Intel 82356SL, 82365SL DF •Vadem VG-365/465/468/469
Dispositivi Flash
•Intel 28F002/004/008/016/032/200/400/800 •Micron 28F161 •AMD Am29F040/080/016/200T/400T/800T •Fujitsu MBM29F040A/080/016/017
Dispositivi Audio
•ProAudio Spectrum •Creative Labs SoundBlaster Pro •Microsoft Sound system •Roland MPU-401
Board support packages
•AMD's Élan evaluation platform •IC Links PC on a stick (Supersized only) •Intel 386EX Evaluation Board •Intel's EXPLR2 evaluation platform •Industrial Control Link's 386EX PC on a Stick •Octagon PC-S10 & 5066 SBCs •Ziatech ZT8902, ZT8904, & ZT8905 SBCs
Modello temporale. Il modello temporale è di tipo time driven e gli eventi esterni sono trattati in modo deterministico dai processi. In particolare QNX mette a disposizione le primitive dello standard POSIX.1 ed alcune dello standard POSIX.1b.
Modello di esecuzione. Il sistema operativo QNX gestisce il ciclo di vita dei processi tramite il processo di sistema process manager (gestore dei processi) che è l'unico processo che condivide lo spazio di indirizzamento con il microkernel. Un processo attraversa quattro fasi, creazione, caricamento, esecuzione e terminazione, tutte gestite dal process manager che si occupa di mantenere le informazioni su tutti i processi presenti sul proprio nodo. Per la creazione esistono tre primitive, fork(), exec(), e spawn(). Quest'ultima, propria del sistema QNX, permette la creazione di un nuovo processo figlio anche su un nodo diverso da quello su cui è stata invocata inviando un messaggio di richiesta al process manager del nodo interessato. Il processo che invoca una fork contatta con un messaggio il process manager, che provvederà a creare il processo figlio allocandogli tutte le risorse necessarie.
Il caricamento di un processo figlio è gestito da un thread del process manager che gira con l'ID del processo figlio, in modo da liberare velocemente il process manager. Tale nuovo processo diventa concorrente di tutti gli altri processi del nodo (compresi i processi di sistema).La terminazione dei processi può avvenire in due modi, con un exit volontaria del processo o con l'arrivo di un messaggio la cui azione è la richiesta di terminazione. La terminazione di un processo padre non implica la terminazione dei suoi processi figli. La fase di terminazione è costituita da due sottofasi: la prima, gestita da un thread con ID del processo invocante, disalloca tutte le risorse usate dal processo rendendole nuovamente disponibili, la seconda, gestita direttamente dal process manager, manda un messaggio al processo padre per avvisarlo della terminazione di un suo processo figlio. Solitamente il processo padre aspetta la terminazione del processo figlio con una wait(), in modo da essere avvisato dopo che quest'ultimo ha svolto il proprio compito, se però la terminazione avviene prima dell'invocazione della wait(), il figlio (ormai senza risorse) non può avvisare il padre della propria exit. Il figlio diviene un processo detto zombie ed entra in stato DEAD fino alla terminazione del padre o una sua wait(). Altri stati in cui si può trovare il processo sono: PRONTO, BLOCCATO, SOSPESO, IN ATTESA. In particolare lo stato BLOCCATO può essere di vari tipi: bloccato su una primitiva di send(), receive(), reply(), signal(), su un semaforo. Il processo in stato SOSPESO è invece sospeso da una primitiva di sigstop e passa a PRONTO su una primitiva di sigcont, lo stato IN ATTESA è invece ottenuto dopo una wait().
Il sistema operativo QNX mette a disposizione diverse primitive per la gestione del tempo di sistema, oltre al tempo universale(data e ora). I processi possono restare in attesa per un intervallo di tempo determinato (in millisecondi), utilizzare timers (temporizzatori) con modalità di tempo assoluto (ora) o relativo (intervalli), nonché settare la risoluzione temporale da 0.5 a 50 millisecondi.
Le interruzioni sono gestite da routine a livello software, attivate da interruzioni hardware, per controllare i dati a basso livello scambiati con le periferiche; lavorano asincronicamente rispetto ai processi cui sono associate e possono essere dotate di priorità fisse per la gestione di più arrivi contemporanei. Nel caso arrivi un'interruzione su cui più processi sono in attesa, non si può determinare un ordine di servizio ed i processi sono serviti in sequenza casuale fino al loro esaurimento.
Struttura del sistema operativo. Lo schedulatore QNX entra in gioco in tre situazioni:
Ai processi è affidata una priorità fissa che può variare da 0 (più bassa) fino a 31, di solito è affidata una priorità 10 ai processi utente creati da shell, che determina quale processo abbia necessità di essere eseguito prima degli altri.
QNX adotta tre algoritmi di scheduling che possono funzionare anche simultaneamente su gruppi di processi dello stesso nodo e che scelgono quale tra più processi concorrenti con la stessa priorità (ed in stato di pronto) debba essere mandato in esecuzione, i processi a priorità più alta, infatti, interrompono quelli a priorità più bassa appena il loro stato passa a pronto.
Il primo permette ai processi di restare attivi, e non interrompibili da processi allo stesso livello, fino a che non effettuano una chiamata di sistema o vengono interrotti da processi a più alto livello permettendo quindi una mutua esclusione tra processi dello stesso livello senza utilizzare semafori.
Il secondo è simile al FIFO, tranne che per l'esistenza di un quanto di tempo, dopo qui il processo viene interrotto e lo schedulatore viene mandato in esecuzione, di solito si hanno timeslice di 50 millisecondi.
Lo schedulatore adattativo è usato di default dai processi della shell e funziona nel seguente modo: riduce di una sola unità la priorità del processo che utilizza tutto il suo quanto di tempo, mantenendola tale fino a che il processo si blocchi volontariamente mentre sta girando. In questo caso la sua priorità è riportata alle condizioni iniziali, incrementandola dell'unità che aveva perso.
Esiste poi la possibilità di fornire una priorità variabile a processi server, in modo che possano acquisire la priorità del client che stanno servendo. Usando la priorità fissa sul server si avrebbe, infatti, un problema di inversione di priorità: se un processo a priorità (per esempio 10) più bassa del server (priorità 20) richiedesse un servizio, sarebbe servito prima di un altro processo a priorità media (priorità 15).
La comunicazione tra i processi è gestita dal microkernel tramite tre tipi di IPC:
IPC via messaggi
IPC via segnali (signal)
IPC via proxy
La IPC via messaggi è il modo fondamentale su cui il sistema si basa e permette la comunicazione sincrona tra processi cooperanti. Un processo che manda un messaggio, richiede la prova dell'avvenuta consegna e possibilmente un reply da parte del ricevente.
Le primitive send(), reply(), receive() sono scritte in C e sono viste come procedure di sistema, in particolare:
La primitiva send() manda un messaggio di lunghezza generica ad un processo destinatario di cui si conosce l'identificatore di processo, dopo di che, il processo mandante è posto in stato bloccato su send fino a quando il messaggio non è arrivato nel recipiente del destinatario. Una volta avvenuto ciò, passa a bloccato su reply fino a che non riceve il messaggio di risposta.
Send (pid, smsg, msg, smsg_len, msg_len)
pid è l'identificatore del processo destinatario
smsg è il buffer di messaggio
msg è il buffer del messaggio di reply
msg_len è la lunghezza del messaggio mandato
smsg_len è la massima lunghezza del messaggio di reply accettata
La primitiva receive() è usata da un processo in attesa di messaggio da parte di un processo che ha invocato una send(). Il suo stato è posto a bloccato su receive fino a che tale messaggio non è ricevuto.
pid = Receive(0, msg, msg_len)
pid è un parametro che la procedura ritorna e contiene l'identificatore del mandante
0 (zero ) indica che si accettano messaggi da qualsiasi processo
msg è il buffer dove il messaggio sarà ricevuto
msg_len è la dimensione massima dei dati accettati dal ricevente
La primitiva reply() è una primitiva non bloccante ed è eseguita atomicamente. Serve a sbloccare un processo che, dopo avere mandato un messaggio, era in stato di bloccato su reply e ad assicurargli il buon esito della trasmissione.
Reply( pid, reply, reply_len )
pid è l'identificatore del processo cui si vuole replicare
reply è il buffer di replica
reply_len è la lunghezza del messaggio di replica
La seguente figura serve a chiarire come il sistema operativo QNX gestisce le tre primitive bloccanti ora viste.
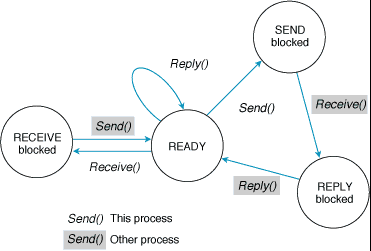
This process (questo processo) è il processo il cui stato è rappresentato nello schema. Le transizioni di stato non evidenziate sono quelle eseguite dopo la chiamata delle primitive da parte del processo considerato.
Other process sono gli altri processi che interagiscono con il processo considerato (This process), causando le transizioni di stato evidenziate.
Alcuni aspetti vanno specificati:
I messaggi non sono copiati nel kernel ma inviati solo quando il ricevente è pronto a riceverli.
Il processo che invoca la reply copia atomicamente il messaggio nel buffer del processo in stato di bloccato su reply.
Chi manda un messaggio non deve sapere nulla sullo stato del ricevente.
Possono essere mandati messaggi di lunghezza generica, al più anche zero.
In caso un processo riceva più messaggi da processi diversi, può decidere di riceverli in ordine di arrivo o in ordine di priorità del mandante.
Sono poi disponibili altre primitive quali la Creceive(), che è simile alla receive, però non blocca il processo in stato di bloccato su receive ma ritorna immediatamente. Primitive per leggere parti del messaggio senza doverlo copiare in altri buffer, per definire più messaggi come parti di un messaggio più grande (nel caso si voglia usare una lunghezza di buffer fissata a priori).
La comunicazione via proxies è usata quando un processo deve mandare un messaggio predefinito ad altri processi senza doversi occupare di riempire ogni volta il recipiente del messaggio e senza bloccarsi in attesa di una risposta. La primitiva qnx_proxy_attach() permette di creare il proxy mentre la trigger() permette di inviare il messaggio contenuto nel proxy.
3. IPC via segnali
L'uso di segnali, utilizzati in molti sistemi operativi per ottenere una comunicazione asincrona tra processi, è fornita anche dal sistema operativo QNX con primitive già' presenti in POSIX, UNIX ed altre proprie. In particolare un processo può definire una funzione (signal handler) che è invocata all arrivo della signal, decidere di ignorarla oppure, nel caso non abbia preso particolari decisioni, essere terminato.
Le signal sono consegnate al processo al quale sono destinate nel momento in cui è posto running, nel caso ci siano più signal pendenti (cioè lanciate e non ancora consegnate al processo destinatario) esse sono fornite in ordine casuale e non in ordine d'arrivo. I segnali possono essere visti come interruzioni software e sono asincrone rispetto all'esecuzione del processo, possono quindi arrivare in istanti non opportuni. Il sistema operativo mette a disposizione funzioni che permettono di bloccare temporaneamente l'arrivo di segnali, che sono lasciati pendenti fino al loro sblocco, senza per questo dovere modificare il tipo di gestione del segnale scelto inizialmente.
Attenzione particolare deve essere posta all'interazione tra segnali e messaggi, infatti, se un processo è bloccato su una send o su una receive ed esiste un signal handler accade la seguente cosa:
Per processi server, su arrivo di un segnale da parte di un client, è possibile scegliere tra due modalità:
1) Gestire il segnale nel modo visto sopra (ritornando un codice d'errore)
2) Bloccare il client in stato di bloccato su signal, svolgere le proprie attività ed in seguito sbloccare il client gestendo il segnale arrivato (il client aspetta che il server lo possa gestire)
La gestione dell'input/output è affidata al processo di sistema Device manager, che utilizza code implementate con memoria condivisa da dispositivi e drivers specifici. Le periferiche sono gestite dai processi di sistema del nodo cui sono collegate, anche su richiesta da parte di processi che risiedono su altri nodi.
Funzionalità di rete. Il sistema operativo QNX possiede un proprio protocollo di rete (FLEET), oltre a garantire la compatibilità con diversi protocolli standard TCP/IP, X.25 e sistemi (NFS, SMB).
FLEET è l'acronimo di:
•Fault-tolerant networking (tollerante ai guasti di rete)
•Load-balancing (bilanciamento automatico)
•Efficient performance (prestazioni efficienti)
•Extensible architecture (architettura espandibile)
•Transparent distributed processing (processazione distribuita trasparente )
In particolare FLEET permette di reindirizzare automaticamente i dati su un'altra rete (nel caso quella in uso cada), senza attivare software delle applicazioni utente. Permette l'utilizzo contemporaneo di diversi tipi di rete con cablaggi separati, l'inserimento dinamico (senza dovere riconfigurare l'intero sistema) di nuovi nodi e nuove reti.
4.5 IL SISTEMA OPERATIVO REAL-TIME CHORUS
Descrizione del sistema operativo. Il sistema operativo Chorus ha un'architettura Component-based, ossia diversi componenti possono essere scelti per ottenere il migliore compromesso tra utilizzo di memoria, prestazioni fornite dal sistema e richieste dell'ambiente esterno. È offerta una famiglia di sistemi operativi con componenti di differente funzionalità e peso (in termini d'occupazione di memoria e primitive implementate). Questo permette un alto grado di scalabilità del sistema. In particolare per sistemi embedded si utilizzeranno pochi componenti (anche personalizzati) sopra un piccolo strato Core executive, mentre per sistemi multi-utente complessi si potranno utilizzare componenti con funzionalità generiche.
Alta affidabilità e prestazioni Real-time sono garantite dal sistema operativo nato per gestire applicazioni di reti di telecomunicazioni, quali PSTN e IP switching.
Sono fornite anche APIs e personalities di differenti sistemi operativi che possono funzionare simultaneamente sulla stessa piattaforma hardware, ciò rende possibile estendere il sistema con applicazioni che utilizzano tali APIs standard (applicazioni RT-POSIX, java runtime e servizi, legacy OS).
In particolare è offerto un supporto per la tecnologia Java, il kit di gestione dinamica (Java DMK) e la tecnologia Jini connection.
Ambiente applicativo. Il sistema operativo Chorus è utilizzato soprattutto nell'ambito delle telecomunicazioni e per applicazioni Real-time embedded, in particolare:
Pubblici e privati switches (PBXs)
Sistemi Datacom
Dispositivi per trasmissione ed internetworking
Reti cellulari
Dispositivi di monitoraggio in rete
Sistemi di trasmissione satellitare
Sistemi di controllo di processo
Hardware e dimensioni del kernel. Per quanto riguarda il Kernel si hanno dimensioni variabili, infatti, il sistema è composto da un kernel executive su cui poggiano vari componenti OS altamente modulari e personalizzabili secondo particolari richieste implementative.
Il Micro core executive supporta:
Utilizzo di singole applicazioni multi-threaded
Gestione personalizzata dall'utente delle Interruzioni, delle Traps e delle eccezioni
Dimensione del Micro core executive di 10 Kbytes
Il core executive supporta:
Applicazioni multiple, utenti indipendenti
Utilizzo di spazi d'indirizzamento in modo utente o supervisore
Gestione dinamica della memoria
Dimensione massima del kernel di 300 Kbytes
Il sistema operativo CHORUS è suddiviso in versioni:
CHORUS/Micro è il più piccolo sistema operativo della famiglia, occupa una decina di Kbytes, e fornisce le sole funzionalità del microkernel. E' utilizzato in sistemi embedded, montati su telefoni portatili e dispositivi tascabili, svolgendo solo applicazioni dedicate, anche con supporto Real-time.
CHORUS/ClassiX è una versione più consistente ed altamente affidabile. Supporta specifiche del sistema operativo legacy e APIs del sistema operativo RT-POSIX. Può essere montato su un unico sistema fornito di più terminali o gestire una rete distribuita di calcolatori. Ogni sistema può gestire applicazioni Real-time che condividono risorse comuni.
CHORUS/MiX è una combinazione di sistema operativo Real-time, nella versione ClassiX, e del sistema UNIX V (versione 4). Applicazioni Real-time e UNIX possono girare ed interagire in modo concorrente sulle stesse macchine, anche distribuite in rete. Questa versione è utilizzata in configurazioni multi sistema.
CHORUS/JaZZ supporta estensioni e servizi Java che includono l'Hot browser e le JavaViews. Permette quindi l'integrazione di Java su supporti Real-time software montati sui dispositivi embedded: schede di commutazione telefonica, lancio di applicazioni software in qualunque punto della rete, ecc.
CHORUS/COOL ORB (Object Request Broker) è la versione OMG (Object Management Group) basata su CORBA 2. Utilizza uno strato di applicazioni integrate che consentono lo sviluppo di applicazioni Real-time distribuite ed object-oriented su sistemi forniti di sistemi operativi eterogenei (Chorus, UNIX, Windows).
Può essere usato sui seguenti processori:
UltraSPARC lli
PowerPC 603, 604, 750, 821, 823, 860, 8260
x86, Pentium
(versione 4.0)
MicroSPARCTM II, IIep, SPARClet, SPARClite
ARM 7TDMI, ARM 710, StrongARM 1100, UltraSPARC IIi
(Versione 3.1 e 3.2)
Modello temporale. La politica di gestione temporale è time driven, ossia è guidata dal clock di sistema, gli eventi esterni sono visti come cambiamenti di stato di variabili interne.
Modello di esecuzione. Il Sistema operativo utilizza un modello a multi-thread sia con task singolo che multiplo, in relazione al tipo di executive caricato. La creazione di nuovi Task (detti attori) può essere fatta utilizzando la primitiva di sistema actorCreate(K), oppure con una fork() su un processo esistente (ereditando tutte le caratteristiche del processo padre). I singoli thread sono forniti di due registri software, di solito contenenti puntatori ad aree di memoria privata, salvati e ripristinati durante i cambi di contesto tra thread.
Il tempo di sistema è gestito in modo da offrire:
timers ad istanti prefissati o periodici (sia in modalità supervisore che utente)
tempo universale (data, ora)
tempo per utilities: servizi di OS ad alto livello, profiling, benchmarking.
Le interruzioni possono essere gestite in modo generico oppure con modalità definite dall'utente. Il tempo di latenza delle interruzioni presenta un valore massimo di circa 400 cicli di clock (dipendente dall'hardware).
Struttura del sistema operativo. Lo scheduling dei processi per la gestione Real-time, ad opera del kernel, è di tipo FIFO a priorità con processi interrompibili dal sistema operativo (preemptive).
Lo scheduling dei processi non Real-time può essere scelta tra quattro politiche (dette classi):
Schedulazione con protocollo FIFO a priorità (preemptive)
Schedulazione con protocollo a priorità' e quanto di tempo fissato
Schedulazione con protocollo UNIX time sharing e Real-time
Schedulazione con politica definita dall'utente
Per quanto riguarda il tempo necessario ad un cambio di contesto, per esempio tra due thread, occorre ricordare che può risultare differente nel caso i thread appartengano a processi utente o supervisore. I processi supervisore condividono lo stesso spazio d'indirizzamento, possedendone una fetta privata, mentre i processi utente utilizzano uno spazio di indirizzamento privato e protetto. Un cambio di contesto a livello utente implica un salvataggio (e recupero) dello spazio d'indirizzamento appropriato e quindi un aumento del tempo necessario (in genere quasi doppio).
La comunicazione tra processi può essere di tipo locale, se i processi sono sulla stessa macchina, ed è implementata in modo sia sincrono che asincrono, oltre che multi-cast (ossia verso più processi).
Se invece è di tipo distribuito, con processi su macchine diverse, il sistema operativo gestisce la trasparenza della locazione dei processi in modo che l'utente li possa trattare come locali.
Il sistema operativo mette a disposizione le Mailboxes con lunghezza dei messaggi configurabile dall'utente ed anche code di messaggi Real-time.
La sincronizzazione avviene tramite l'uso di variabili Mutex (per la mutua esclusione), semafori, flag su eventi e, per quanto riguarda il Real-time, Real-time Mutex (che evitano il problema della inversione di priorità). Le applicazioni a livello supervisore possono utilizzare primitive per lo scambio di brevi messaggi. Altre primitive di sincronizzazione, quali variabili condizionali, possono essere implementate usando tali primitive base. Un servizio di sincronizzazione distribuita, costruito sopra il kernel e residente su un server, utilizza solo variabili Mutex per implementare un algoritmo basato sul passaggio di un token (gettone) tra i vari processi. Tale algoritmo si occupa principalmente di gestire la creazione/distruzione del token e ne permette la condivisione tra un gruppo di clients.
La gestione della memoria può essere fatta direttamente sulla memoria fisica, senza protezione, per applicazioni in cui occorra una memoria condivisa con basso tempo d'accesso da parte dei processi.
Può essere a spazzi d'indirizzamento multipli e protetti, con paginazione, oppure di tipo virtuale.
Il sistema operativo Chorus permette la gestione di files in diversi standards quali:
UFS e FFS file systems (compatibili con UNIX)
Flash File System, basato su MS-DOS file system (con nomi lunghi)
Drivers per SCSI e IDE controllers e Flash Memory
NFSTM file sharing (client e server)
Esecuzione di files binari salvati in Flash Memory
ANSI-C stdio
Funzionalità di rete. Sono supportati diversi protocolli di rete quali:
TCP/UDP/IP, in particolare con: supporto d'interfacce di rete multiple, Routing tra le interfacce multiple, IP forwarding ed IP multi-cast.
Sockets.
SLIP, PPP, con demand-dial per la creazione della connessione.
Serial lines: line disciplines, pseudo-tty.
DHCP.
Name servers (DOMAIN, IEN116, file-based).
rsh, Xclients (Xlib, Xt, Xmu, Xext, Xaw).
Sun RPC, Ethernet, Serial line, VME-backplane e supporti per cPCI.