Capitolo 5: OSE Real-Time Operating System
5.1.1 Categorie
5.1.2 Stati
5.1.3 Principi di Scheduling
5.1.4 Tipi
5.1.5 Priorità
5.2 INTERPROCESS COMMUNICATION
5.2.1 Segnali
5.2.2 Semafori veloci (fast semaphores)
5.2.3 Semafori
5.4.1 Interrupt hardware
5.4.2 La facility wakeup
5.4.3 Interrupt temporali ( timer interrupt )
5.4.4 Handlers
5.5.1 La gestione della memoria
5.5.2 User Number
5.5.3 Controllo degli errori
5.6.1 Demone del sistema
5.6.2 Demone di ricerca (hunt deamon)
5.6.3 Tick deamon
5.6.4 Local Debugger Module (LDM)
5.7 MODALITA’ DI PARTENZA DEL SISTEMA
5.7.1 Cold Start
5.7.2 Warm Start
5.7.3 Hot Start
5.8.1 Ambiente multi-CPU
5.8.2 Link handlers
5.8.3 Processi fantasma e canali logici
5.8.4 Chiamate di sistema remoto
Descriviamo ora il sistema Enea OSE, cercando prima di dare un’idea di che cos’è e di come può essere usato per risolvere problemi real-time sia semplici che complessi. Inizialmente daremo alcune definizioni e cercheremo di mettere in luce alcuni concetti fondamentali.
I processi e i principi della comunicazione fra processi ( interprocess communication ) sono le parti basilari di ogni sistema operativo real-time. Quindi la conoscenza di queste parti è cruciale per mettersi in grado di progettare un sistema basato su OSE.
Il più importante blocco costruttivo in un sistema OSE è il processo, visto che è attraverso l’uso dei processi che un sistema alloca tempo di CPU. In un sistema OSE si possono trovare diverse categorie e tipi di processi. Questi sono tutti attentamente progettati in modo da complementarsi a vicenda per soddisfare ogni possibile esigenza in un sistema.
5.1.1 Categorie
Processi Statici
La categoria dei processi statici è quella più comunemente usata nei sistemi di piccola e media dimensione. I processi statici sono creati alla partenza del sistema dal kernel, o dalla libreria d’interfaccia se essi risiedono in una unità software collegata separatamente. Si suppone che essi esistano "per tutto il tempo", cioè la vita del sistema o della unità software. Non è permesso ad alcun processo di uccidere un processo statico. Un processo statico può essere ucciso solo se è parte di una unità software collegata e caricata separatamente, e soltanto come parte di un’operazione che uccide tutti i processi in quell’unità.
Processi Dinamici
All’opposto dei processi statici, ci sono processi dinamici che possono essere creati e uccisi liberamente run-time.
Lo scopo principale di avere processi dinamici è che consente al sistema di far girare istanze multiple dello stesso codice, dove il numero delle istanze non deve essere conosciuto compile-time.
I processi dinamici possono anche essere usati per preservare lo spazio nello stack, visto che esso è usato soltanto quando il processo esiste.
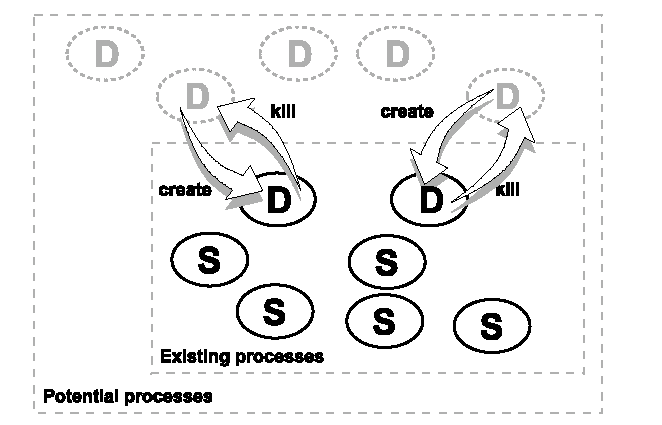
Figura 5.1. Questa figura mostra il dominio dei processi in un sistema OSE. L’area interna illustra tutti i processi correntemente esistenti dove ‘D’ sta per dinamici e ‘S’ per statici. Tutti i processi dinamici possono essere creati e uccisi run-time. Ciò è illustrato dalle frecce tra le aree interna (esistenti) ed esterna (potenziali).
5.1.2 Stati
Un processo in OSE è sempre in uno dei seguenti stati:
In esecuzione
La CPU è correntemente assegnata a questo processo. In un sistema a singolo processore, solo un processo può essere in questo stato in un certo istante.
Pronto
Tutti i processi pronti per essere eseguiti sono posti in una coda . Ad ogni switch del processo il primo processo nella coda è schedulato per l’esecuzione.
Ogni livello di priorità dei processi ha la sua coda. Tutti i processi in una coda vogliono essere eseguiti ma non gli è permesso perché un processo di priorità maggiore o uguale è correntemente eseguito.
In attesa
Il processo sta aspettando che accada un evento oppure è stato fermato. I processi in attesa al momento non hanno bisogno della CPU.
Un processo può essere nello stato di attesa per i seguenti motivi:
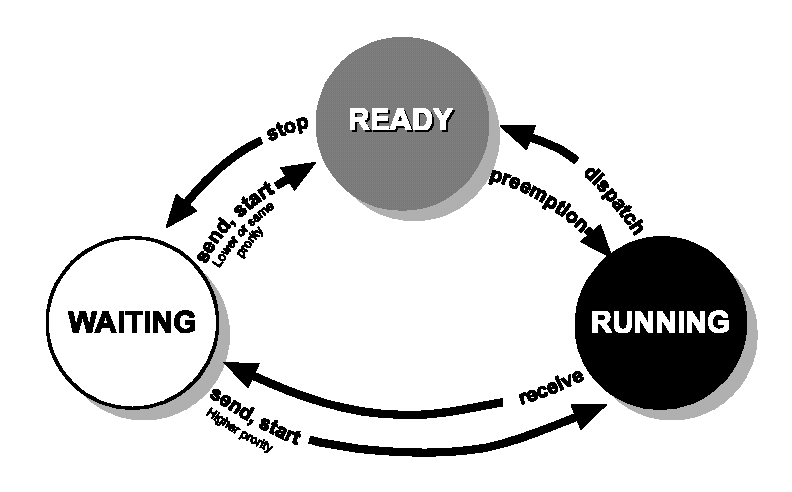
Figura 5.2. Un processo OSE cambia stato run-time secondo le azioni e le condizioni illustrate
Questi sono i diversi principi di scheduling usati in OSE:
Pre-emptive
Il sistema operativo può interrompere (pre-emption) il processo corrente in ogni momento, anche se esso sta eseguendo una chiamata di sistema, cioè il sistema operativo può passare ad eseguire un altro processo in ogni istante. Tutti i processi in OSE usano questo metodo di scheduling.
Ciclico
I processi possono essere schedulati per essere eseguiti a certi intervalli di tempo. Questo metodo di scheduling è usato per i processi timer-interrupt in OSE.
Priority Based
Il processo con la più alta priorità sarà eseguito finchè non ci sono interrupt in servizio e il processo non sta aspettando che si verifichi qualche evento. Questo metodo di sheduling è usato per tutti i processi prioritizzati in OSE.
Round Robin
Per dare a tutti i processi ad un certo livello di priorità uguale diritto alla CPU ogni livello di priorità ha una coda contenente tutti i processi pronti per quel livello di priorità. Il primo processo nella coda è il processo correntemente in esecuzione su quel livello di priorità. Quando un processo perde il suo diritto ad essere il primo processo nella coda sarà posto in fondo alla coda e non sarà eseguito finchè non raggiungerà di nuovo la testa.
In OSE sia i processi prioritizzati che i processi in background usano questo principio di scheduling, con una grossa differenza. Mentre un processo prioritizzato è posto alla fine della coda dei processi pronti del suo livello di priorità ogniqualvolta esso sospende se stesso, questo non accade per un background process fino a che non è finito il suo time slice.
5.1.4 Tipi
Processi Interrupt
Sono chiamati processi interrupt quelli in risposta ad un hardware interrupt o ad un evento software e saranno in esecuzione ogni volta dall’inizio alla fine, a condizione che nessun altro processo interrupt con una priorità maggiore debba essere eseguito, nel qual caso il processo interrupt con priorità maggiore otterrà la CPU. Il processo interrupt con priorità minore continuerà di nuovo quando quello a priorità maggiore avrà completato il suo lavoro. I processi interrupt sono scritti come normali subroutines e hanno sempre una priorità maggiore di ogni processo prioritizzato o background. I processi interrupt sono chiamati in ordine di priorità, il che significa che un processo interrupt può essere interrotto da un altro processo interrupt con priorità maggiore.
Processi Timer Interrupt
I processi timer interrupt si comportano esattamente allo stesso modo di un processo interrupt ordinario, eccetto che essi vengono chiamati in risposta a cambiamenti nel timer di sistema.
Ciò significa, per esempio, che un progettista del sistema può specificare che un certo processo timer interrupt debba essere eseguito a intervalli di un secondo. Anche i processi timer interrupt sono chiamati in ordine di priorità, come i processi interrupt ordinari.
Processi Prioritizzati
I processi prioritizzati sono il tipo più comune di processo. Essi sono scritti come loop infiniti che saranno eseguiti finchè non vi è un processo interrupt o un altro processo prioritizzato con priorità maggiore pronto.
Processi Background
I processi background girano in modalità strettamente time sharing ad un livello di priorità inferiore ai processi prioritizzati. Ciò significa che un processo background può essere interrotto da un processo prioritizzato o interrupt in ogni istante. Sono anch’essi scritti come loop infiniti, allo stesso modo dei processi prioritizzati.
Il meccanismo del time slice nei processi background viene usato per distribuire la potenza di calcolo della CPU tra un certo numero di processi. Quando un processo background comincia ad essere eseguito con un time slice nuovo esso non sarà costretto a lasciare la CPU a favore di un altro processo background fino a che il suo time slice non è terminato. Ciò significa che se un processo background sospende se stesso e diventa di nuovo pronto prima che il suo time slice sia terminato, esso semplicemente continuerà l’esecuzione fino alla fine del suo time slice. Quando un processo background ha consumato il suo time slice esso sarà interrotto e posto alla fine della coda dei processi background pronti. A questo punto al primo processo in tale coda viene dato un time slice nuovo e comincia ad essere eseguito.
Processi fantasma
Un processo fantasma non contiene alcun codice eseguibile ed è quindi incapace di ricevere alcun segnale. Se un segnale inviato a un processo fantasma non è rediretto da una tabella di redirezione esso verrà perso e lo spazio in memoria che occupava sarà liberato.
I processi fantasma sono principalmente usati insieme ad una tabella di redirezione per formare una parte di un canale logico quando si comunica attraverso target boundaries. Maggiori informazioni si potranno trovare più avanti quando parleremo dei link handlers e dei canali logici.
Figura 5.3. Riassunto sui processi OSE. Si noti che i processi fantasma non sono mostrati in figura, perché essi sono soltanto un’immagine vuota di qualche altro tipo di processo reale.
E’ possibile assegnare una certa priorità ad ogni processo. I valori permessi di priorità sono 0-31, dove 0 rappresenta la priorità più alta. E’ importante ricordare che il valore di priorità ha un diverso significato per i diversi tipi di processo. Descriviamo ora queste differenze.
Processi interrupt
Per i processi interrupt, la priorità è mappata ad una priorità hardware. E’ essenziale settare la priorità di un processo interrupt alla corrispondente priorità hardware, altrimenti il sistema non si comporterà come richiesto.
Processi timer interrupt
Per i processi timer interrupt il valore di priorità indica l’importanza dell’evento temporale, cioè se due o più processi timer interrupt sono schedulati per cominciare l’esecuzione esattamente nello stesso istante, l’ordine con il quale verranno eseguiti dipenderà dalla loro relativa priorità.
Processi prioritizzati
Nel caso di un processo prioritizzato il valore di priorità descrive semplicemente le esigenze in termini di tempo di risposta per i processi. Un processo con una priorità più alta è più "responsivo" dal momento che viene eseguito prima di ogni processo con priorità più bassa.
Processi background
Il valore di priorità non è usato per i processi background.
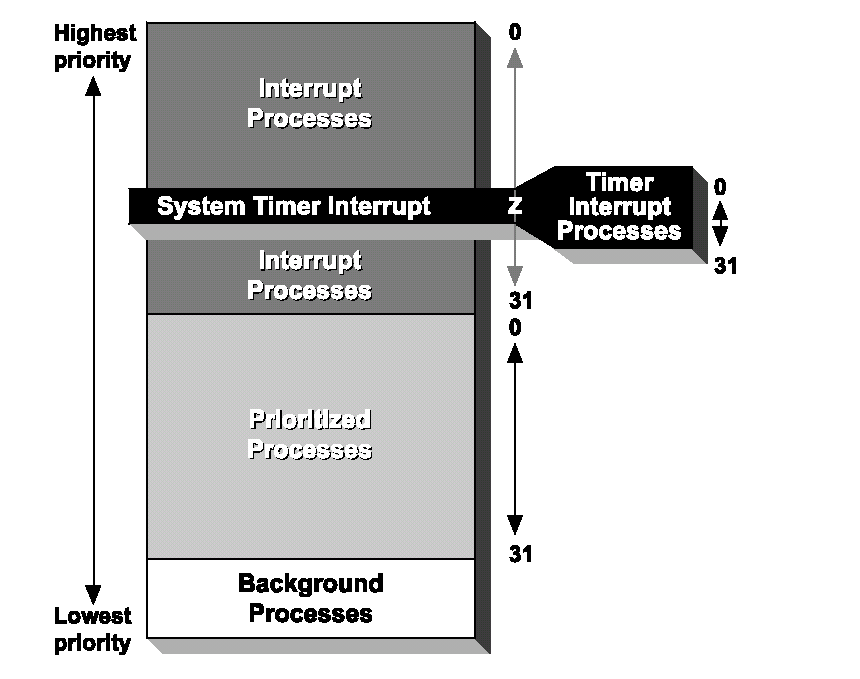
Figura 5.4. Questo è lo schema di priorità dei processi in OSE. Si noti che tutti i processi timer interrupt girano sulla priorità Z, che è la priorità hardware del timer di sistema.
5.2 INTERPROCESS COMMUNICATION
In OSE ci sono diversi modi per far comunicare o sincronizzare i processi. Anche se tutte le funzioni di comunicazione fra processi possono essere realizzate dalla gestione dei segnali, che è il modo raccomandato per far comunicare due processi, ci possono essere momenti in cui gli altri meccanismi sono più adatti.
Descriviamo ora tutti i meccanismi per la comunicazione fra processi disponibili in OSE.
5.2.1 Segnali
Considerazioni generali
Un segnale è un messaggio che è spedito da un processo ad un altro.
Prima di comunicare con un altro processo è necessario conoscere l’identità di quel processo.
I processi statici possono essere dichiarati come pubblici, e ogni altro processo che vuole comunicare con quel processo può dichiararlo come esterno e così ottiene l’identità del processo.
Ai processi dinamici viene data un’identità quando sono creati ed ogni processo che voglia comunicare con un processo dinamico deve determinare l’identità del processo destinazione.
Così se un processo diverso dal creatore vuole comunicare con un processo dinamico, l’identità del processo può essere determinata comunicando con il suo creatore.
L’utente deve anche allocare un buffer di memoria per il segnale da un pool di memoria prima che esso possa spedire il segnale. E’ anche possibile usare il buffer da un segnale ricevuto se la dimensione del buffer è abbastanza grande.
La prima allocazione del buffer conterrà il numero del segnale ( tipo del segnale ) ed ogni dato da spedire sarà allocato immediatamente dopo il numero del segnale.
Il concetto di pool verrà descritto quando parleremo della gestione della memoria.
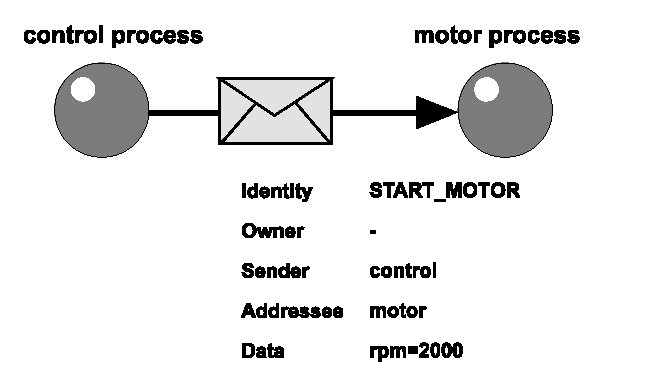
Figura 5.5. Questa figura mostra gli attributi di un segnale che sta per essere inviato dal control process al motor process. Si noti che il campo owner cambia da "control" a "motor" quando il segnale viene spedito .
Oltre al numero del segnale e ai dati tutti i segnali hanno alcuni attributi nascosti ad essi associati: questi sono gli attributi owner, size, sender e addressee. Questi attributi possono essere esaminati usando chiamate di sistema. Gli attributi possono anche cambiare usando certe chiamate di sistema.
Per esempio, la chiamata di sistema send cambia l’owner di un buffer di segnale dal processo trasmittente al processo ricevente. Setta anche gli attributi sender e addressee del segnale.
Quando un processo guadagna l’accesso a un buffer o allocandolo o ricevendolo, il processo diventa il proprietario del buffer. Soltanto il proprietario può compiere operazioni sul buffer. Una volta che un segnale è stato spedito ad un altro processo, il processo trasmittente non vi può più fare accesso.
Ciò avviene per eliminare i conflitti.
Un processo può specificare quali segnali è interessato a ricevere in un certo particolare momento. Ciò è fatto passando un array di numeri di segnali ad una routine ricevente. Il processo può quindi o aspettare che qualcuno dei segnali specificati arrivi o controllare se qualcuno di essi è nella coda dei segnali del processo. Altri segnali ( quelli che per il momento non interessano ) saranno lasciati nella coda dei segnali del processo ricevente. Se un certo segnale non è nella coda dei segnali e il processo vuole aspettare il suo arrivo, un altro processo passerà in esecuzione ( verrà eseguito un cambiamento di contesto ). E’ anche possibile per un processo essere interessato a tutti i segnali e in tal modo riceverà ogni segnale nella sua coda dei segnali.
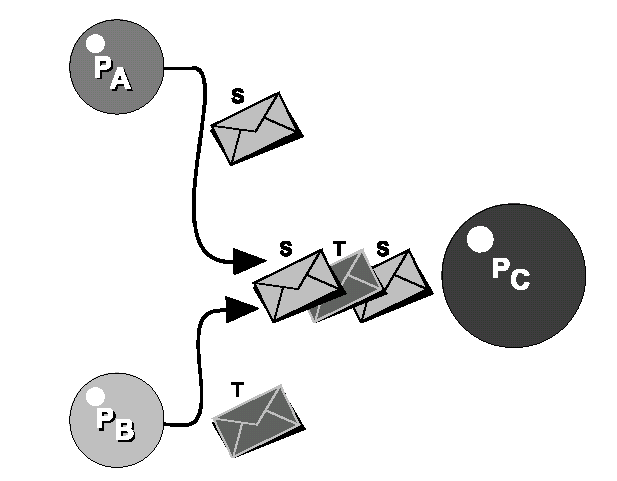
Figura 5.6. Tutti i processi hanno una singola coda di ingresso per i segnali ricevuti. OSE permette al processo C di scegliere il tipo di segnali che vuole prelevare dalla sua coda di ingresso in ogni momento.
Se un processo con alta priorità sta aspettando un segnale e un processo con priorità più bassa spedisce quel segnale , il processo trasmittente è immediatamente interrotto e il processo con priorità più alta che riceve il segnale comincerà ad essere eseguito.
Ci sono alcune restrizioni sullo scambio di segnali fra processi, di cui però non parliamo.
Si noti che se un processo viene ucciso un altro processo comunicante con il processo ucciso verrà informato di ciò solo se esso ha fatto un attach al processo ucciso.
Il sistema degli attach verrà discusso in seguito quando parleremo dei link handlers.
Redirezione di un segnale
In alcuni rari casi i segnali possono dover essere processati da un processo diverso da quello a cui sono stati spediti. Per questo scopo i processi possono opzionalmente essere dotati di una "tabella di redirezione".
La tabella di redirezione è una struttura dati contenente una lista di numeri di segnali e delle corrispondenti identità dei processi.
La tabella di redirezione deve essere specificata quando il processo viene creato. Per ogni segnale spedito al processo tale tabella viene scandita. Se il numero del segnale viene trovato nella tabella, il kernel guarda nella tabella per determinare il processo corrispondente, e ridirige il segnale a quel processo. Se il processo associato ha anch’esso una tabella di redirezione, la procedura verrà ripetuta fino a che il segnale non raggiunge un processo.
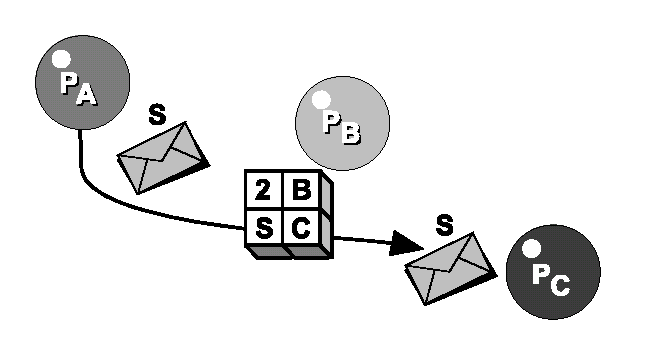
Figura 5.7. Un segnale S spedito al processo B può, con l’uso di una tabella di redirezione connessa al processo B, essere spedito al processo C. Si noti che la prima riga nella tabella di redirezione contiene un’informazione sul numero totale di righe nella tabella stessa. La seconda colonna nella prima riga ci dice a quale processo tutti i messaggi dovrebbero essere spediti se non sono esplicitamente menzionati nella tabella di redirezione.
E’ importante tenere in mente che il campo addressee nell’area di amministrazione del segnale è ugualmente tenuto. Indipendentemente da quante redirezioni vengono fatte, è sempre possibile ottenere il destinatario originale con la chiamata di sistema addressee , e il trasmittente con la chiamata di sistema sender.
Il kernel ha un meccanismo di detection per evitare cicli infiniti . Si ha un ciclo infinito se una tabella di redirezione fa ridirigere un segnale a un processo precedente nella catena di redirezione. In questo caso tutte le tabelle di redirezione sono ignorate, e il segnale viene spedito al processo specificato nella chiamata di sistema send.
La principale ragione per avere tabelle di redirezione è di usarle nei link handlers, rendendo possibile catturare e gestire segnali spediti da clienti a processi fantasma rappresentanti processi reali in un altro sistema target. Descriveremo più avanti i link handlers.
Un secondo importante modo di usare le tabelle di redirezione è di instradare segnali all’interno dello stesso blocco. Il concetto di blocco verrà pienamente descritto più avanti nella parte sulla gestione della memoria. La sola cosa che è necessario conoscere sui blocchi a questo punto è che essi possono essere costituiti da diversi processi e possono anche contenere un processo dedicato con una tabella di redirezione. Usando questi meccanismi è possibile per qualcuno spedire un segnale al processo principale del blocco senza conoscere la struttura sottostante di tutti gli altri processi nel blocco. Con la tabella di redirezione tale processo è capace di instradare un segnale entrante verso la sua giusta destinazione. Questa struttura sottostante del blocco può cambiare in modo significativo ma l’interfaccia verso il mondo esterno rimarrà la stessa.
5.2.2 Semafori veloci (fast semaphores)
Ogni processo ha un "fast semaphore". La ragione per cui si usano semafori veloci per la sincronizzazione dei processi è che essi sono più veloci dei segnali. Tuttavia, non sono potenti come i segnali , perché ad essi manca la capacità di trasportare dati e inoltre non possono essere rediretti.
Un semaforo veloce deve sempre essere esplicitamente inizializzato prima che possa essere usato.
Dopo l’inizializzazione un semaforo veloce è principalmente gestito da due chiamate di sistema,
wait_fsem e signal_fsem e può occasionalmente essere esaminato con get_fsem.
L’operazione di wait decrementa il valore del semaforo e blocca il processo se il risultato diventa negativo. Si noti che un processo può soltanto eseguire un’operazione di wait sul suo proprio semaforo veloce e ai processi interrupt non è permesso eseguire alcuna operazione di wait.
Un processo sarà bloccato fino a che un altro processo non renderà il valore del semaforo veloce non negativo attraverso un’operazione di signal.
Se un processo esegue un’operazione signal_fsem su un semaforo veloce di un processo con priorità più alta, esso sarà immediatamente interrotto, e il processo con priorità più alta comincerà ad essere eseguito.
Si noti che le operazioni su un semaforo veloce di un processo interrupt si comportano diversamente dalle operazioni sui semafori veloci di altri tipi di processo. Un processo interrupt non può, per esempio, compiere alcuna operazione di wait. Tutti gli altri processi eccetto quelli fantasma possono, tuttavia, fare una signal su un semaforo veloce di un processo interrupt, e quindi invocare un evento software.
Il meccanismo dell’evento software è una caratteristica con la quale è possibile per ogni processo cambiare lo stato di un processo interrupt a pronto. Questo può essere molto utile, per esempio nel debugging di processi interrupt.
Descriveremo più in dettaglio gli eventi software quando parleremo della gestione degli interrupt.
I semafori sono qualcosa di simile ai semafori veloci, ma essi differiscono in un aspetto importante.
Un semaforo non è collegato ad alcun specifico processo. Ogni processo background o prioritizzato può fare una wait su un semaforo, non soltanto il proprietario. Ogni tipo di processo eccetto quelli fantasma può fare una signal su un semaforo.
Lo scopo principale dei semafori è di proteggere sezioni critiche di codice da un’esecuzione concorrente ( la cosiddetta mutua esclusione ) senza disabilitare gli interrupt. Questo è spesso fatto per proteggere risorse globali condivise. Se il compilatore supporta una inizializzazione statica delle strutture C questa può essere usata per dichiarare un semaforo compile-time.
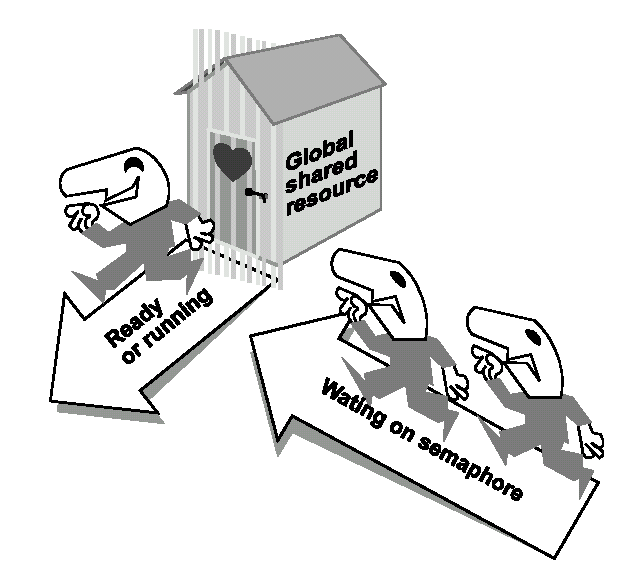
Figura 5.8. Lo scopo principale di usare un semaforo è di assicurare che soltanto un processo in un certo istante sta usando una risorsa globale condivisa. Non appena il processo che sta correntemente occupando la risorsa la rilascia essa sarà automaticamente assegnata al prossimo nella sua coda di attesa. Si usa la chiamata di sistema wait sem per mettersi in coda per usare la risorsa il prima possibile e la chiamata di sistema signal sem per rilasciarla non appena la risorsa non è più necessaria.
Sono chiamate variabili ambientali delle stringhe attaccate o a un blocco o a un processo. Queste variabili possono essere create o modificate run-time e sono usate dalle applicazioni per immagazzinare informazioni di stato o di configurazione associate ad uno specifico blocco o processo. Lo scopo principale delle variabili ambientali è di configurare il processo che possiede la variabile ambientale. Esse possono, tuttavia, anche essere usate per diffondere certe informazioni a tutti i processi in un blocco in run-time, evitando quindi il pesante lavoro di spedire un segnale dedicato a tutti i processi in questione.
Si noti che un processo figlio non erediterà le variabili ambientali del processo padre, ma un blocco creato da un certo processo erediterà tutte le variabili ambientali del blocco in cui il processo creatore è collocato.

Figura 5.9. Il meccanismo di comunicazione delle variabili ambientali può essere visto come un messaggio su una lavagna nella stanza di una famiglia. Un membro della famiglia scrive un messaggio che è leggibile da tutti gli altri membri della famiglia. Ogni membro della famiglia può cambiare il messaggio sulla lavagna in ogni istante.
Un interrupt è un modo di mandare in esecuzione un processo interrupt separato il prima possibile dopo che è successo un certo evento. Non succede sempre che l’esecuzione ( dopo che un interrupt è stato servito ) continuerà da dove si trovava quando c’è stato l’interrupt. Una qualche operazione nel processo interrupt potrebbe ad esempio aver reso pronto un processo prioritizzato. Se quel processo ha un livello di priorità maggiore del processo interrupt, l’esecuzione continuerà in quel processo. In un sistema OSE ci sono tre possibili modi in cui un processo interrupt può essere attivato: attraverso un vero hardware interrupt, attraverso un evento software o attraverso un evento temporale.
Un processo interrupt può naturalmente essere attivato da qualche evento hardware esterno. In questi casi è assolutamente cruciale che i livelli dell’interrupt hardware della CPU corrispondano con le priorità logiche dell’interrupt in un sistema OSE.
Gli eventi software sono realizzati o spedendo un segnale a un processo interrupt o semplicemente facendo una signal su un semaforo veloce del processo interrupt. Questo è chiamato risveglio (waking up) del processo interrupt.
Il processo interrupt può dirci la differenza tra un interrupt hardware e i due tipi di eventi software attraverso la chiamata di sistema wake up.
Si noti che il kernel garantisce una chiamata wakeup per ogni evento software o interrupt hardware.
Si noti anche che tutte le routine di interrupt vengono eseguite dall’inizio alla fine ( non c’è differenza se la chiamata è dovuta a un interrupt hardware o a un evento software ).
La sola cosa che può interrompere un processo interrupt è un altro interrupt o evento ad un livello di priorità maggiore.
La ragione di avere eventi software e la facility wakeup è che essi riducono in modo significativo la difficoltà di scrivere e fare il debugging di device drivers.
Normalmente i processi interrupt sono schedulati soltanto da un interrupt hardware esterno, rendendoli difficili da controllare.
Un buon esempio è quando si scrive un device driver per qualche hardware di trasferimento seriale.
L’hardware genererà un interrupt quando il registro di trasmissione è vuoto, essendo il problema quello di porvi il primo carattere. Questo problema è eliminato in OSE dal momento che è possibile spedire segnali a un processo interrupt. Quando si vuole trasmettere una stringa, basta spedire il primo carattere in un segnale al processo interrupt e porre il resto in un buffer. Il processo interrupt può allora, con una chiamata a wake_up, determinare che esso ha ricevuto un segnale e trasmettere quel primo carattere.
In seguito esso riceverà veri interrupt hardware che scheduleranno il processo interrupt e svuoteranno il resto del buffer di trasmissione.
Un’altra soluzione potrebbe essere quella di porre tutti i caratteri in un buffer e poi cominciare la trasmissione attraverso una signal sul semaforo veloce del processo interrupt.
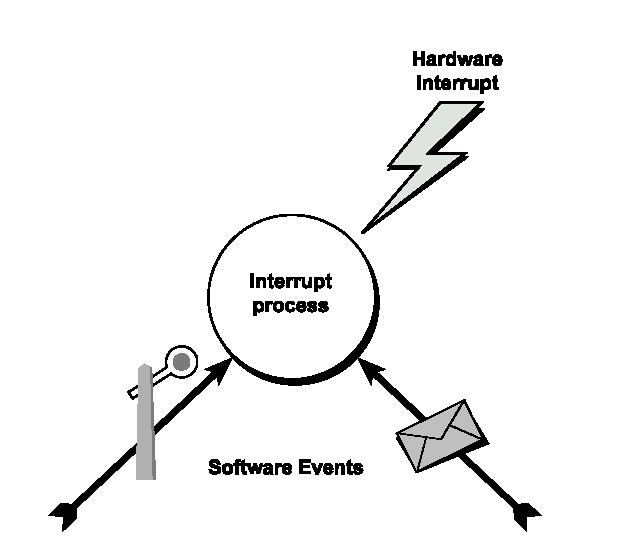
Figura 5.10. Un processo interrupt può essere schedulato da un vero interrupt hardware, da un evento software come spedire un segnale al processo interrupt, o da una signal sul semaforo veloce del processo interrupt.
5.4.3 Interrupt temporali ( timer interrupt )
I processi timer-interrupt sono identici ai processi interrupt ad eccezione del modo in cui sono chiamati.
Un time slice che rappresenta il numero di millisecondi tra ciascuna attivazione del processo è specificato quando il processo timer-interrupt viene creato.
Inoltre, tutti i processi timer-interrupt in un sistema sono mutuamente esclusivi e la loro importanza può essere definita assegnando ad essi differenti priorità.
I processi timer-interrupt sono dipendenti dal tick counter del sistema. Questo contatore è avanzato dalla chiamata di sistema tick. Ogni volta che il tick counter del sistema è avanzato il kernel controlla se deve partire un timer interrupt, o se si deve cambiare lo stato di qualche altro processo da in attesa a pronto. Dal momento che la partenza di un timer interrupt dipende dal tick counter del sistema la chiamata di sistema tick non può essere eseguita dall’interno di un processo timer interrupt.
Invece tale chiamata può essere fatta da un ordinario processo interrupt attivato da qualche timer hardware esterno.
Si noti che è molto importante mantenere i processi timer interrupt i più brevi possibile. Questo perché la somma dei tempi di esecuzione di tutti i processi timer interrupt deve essere minore di un tick di sistema, altrimenti il sistema perderà un tick di sistema. Una soluzione ai problemi di timing nei processi di interrupt può essere quella di muovere parti del codice in un processo interrupt verso un processo prioritizzato. Il processo interrupt può quindi eseguire il lavoro più urgente e terminare facendo una signal al processo prioritizzato che subentrerà.
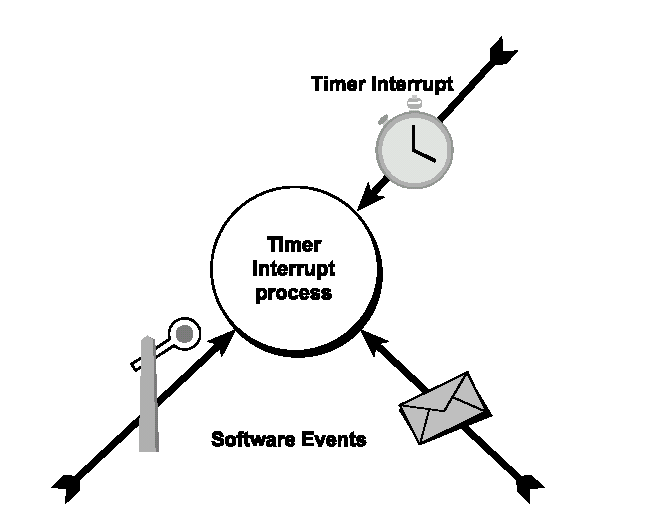
Figura 5.11. Un processo timer-interrupt può essere schedulato ciclicamente da certi intervalli di tempo, da un evento software come spedire un segnale al processo timer interrupt o facendo una signal sul semaforo veloce del processo timer-interrupt.
E’ spesso desiderabile scrivere routines per cambiare il comportamento o aggiungere funzionalità a qualche chiamata di sistema OSE. Qualche volta è anche necessario scrivere codice per configurare il kernel. Tutto ciò è fatto scrivendo handlers. Di essi parleremo più avanti.
Ci sono molti aspetti della sicurezza di un sistema. Cercheremo di rispondere alle seguenti domande:
Altri aspetti, ad esempio come creare un canale di comunicazione fault-tolerant tra due processi, sono descritti nella parte sui link handlers e i processi fantasma.
5.5.1 La gestione della memoria
In OSE ci sono diversi "gruppi di memoria". Non è necessario conoscere ogni cosa su tutti i gruppi di memoria per costruire un sistema semplice. Alcuni di essi sono principalmente rivolti a sistemi complessi con molti processi che usano meccanismi hardware per la gestione e la protezione della memoria. Tuttavia, è cruciale sapere che un pool è un’area di memoria dalla quale buffer di segnali, stacks e aree del kernel sono allocate. In un sistema OSE c’è sempre un pool di memoria "globale" chiamato system pool. Il progettista del sistema potrebbe anche voler creare pool "locali" che in questo caso risiedono nello stesso spazio di memoria dei processi che supportano.
OSE System Pool
Il primo pool creato è il system pool. Due cose rendono questo pool speciale: la sua esistenza è cruciale per il kernel ed esso deve sempre essere allocato nella memoria del kernel. E’ possibile lasciare a tutti i processi di allocare ciò di cui essi hanno bisogno da questo pool globale. Ciò, tuttavia, ha un grosso svantaggio. Se il system pool è rovinato, l’intero sistema fallirà.
Blocchi
OSE permette di raggruppare insieme un certo numero di processi in un blocco. Un blocco di processi può avere un suo proprio pool di memoria, oppure essi possono allocare memoria dal pool globale del sistema. Se un pool è rovinato, questo condizionerà soltanto i blocchi connessi a quel pool, e i processi in quei blocchi. I processi negli altri blocchi continueranno normalmente, fino a che essi non verranno a dipendere da qualche processo che a sua volta dipende dal blocco rovinato. Quando un processo viene creato, il chiamante stabilisce di quale blocco il nuovo processo deve essere considerato parte. Normalmente si vorrebbe che il processo figlio faccia parte dello stesso blocco del processo padre.
Spesso è conveniente vedere tutti i processi in un blocco come un processo omogeneo perché molte chiamate di sistema che operano su singoli processi lavorano anche su interi blocchi. E’ ad esempio possibile far partire ( start ) o uccidere ( kill ) tutti i processi in un blocco con una singola chiamata di sistema. Un altro esempio è la capacità di spedire segnali tra blocchi di processi invece che tra processi individuali all’interno del blocco. Il blocco di processi può comportarsi in questo caso come un router e trasferire il segnale a qualche specifico processo all’interno del blocco. I processi all’interno dello stesso blocco possono sempre comunicare tra di loro.
Raggruppare processi in blocchi migliora la struttura del sistema. Ciò è utile specialmente nei sistemi più grandi e più complessi.
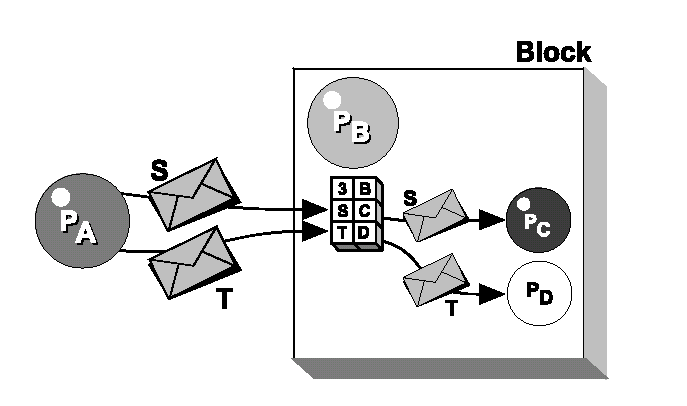
Figura 5.12. Questa figura illustra come la tabella di redirezione del processo B può cambiare la destinazione di certi segnali spediti al processo B. Il significato della prima riga della tabella di redirezione è stato discusso nella figura 7.
Segmenti
Normalmente quando si trasferiscono segnali il processo trasmittente spedisce solo un puntatore a un buffer di segnali nel suo pool. Il processo ricevente usa questo puntatore per accedere al buffer di segnali. Questo ha il vantaggio di rendere veloce il sistema, ma c’è anche il pericolo che il processo ricevente distrugga il pool del processo trasmittente. Questa situazione può essere alquanto migliorata permettendo ad uno o più pool di essere posizionati insieme in un singolo segmento separato. I processi comunicanti che usano pool diversi nello stesso segmento possono ancora accedere alla memoria negli altri pool ma possono allocare memoria solo nel loro pool.
Se un segnale è spedito tra processi che usano pool collocati in diversi segmenti, l’utente può scegliere tra il trasferimento del solo puntatore oppure copiare il buffer di segnale. La seconda possibilità viene scelta per supportare la sicurezza del sistema. Si sceglie questa modalità settando il modello di memoria a 1 nel file di configurazione del kernel. Il softkernel supporta solo il modello di memoria 1.
Bisogna rendersi conto che la piena sicurezza può essere raggiunta soltanto se i pool sono posti in diversi segmenti e i segmenti sono isolati da una MMU (Memory Management Unit).
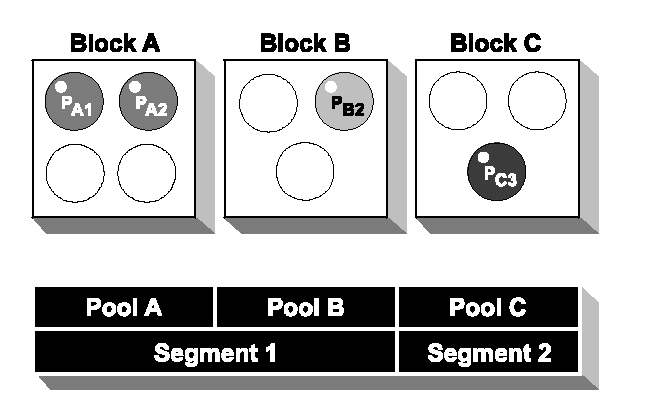
Figura 5.13. Per migliorare la struttura di una applicazione, è possibile raggruppare i processi in blocchi separati. Tutti i processi in un tale blocco condivideranno lo stesso pool di memoria. La protezione e la gestione hardware della memoria può essere raggiunta posizionando uno o più pool in un segmento di memoria.
OSE supporta " user numbers " per proteggere unità software funzionalmente separate l’una dall’altra.
Gli user number sono delle etichette di identità usate per incrementare la sicurezza del sistema dividendo processi e blocchi in categorie. Ogni processo è associato ad un certo user number. Solo processi con lo stesso user number possono comunicare, influenzarsi a vicenda attraverso chiamate di sistema o anche prendere conoscenza della reciproca esistenza. Ci sono, tuttavia, due importanti eccezioni a questa regola. I processi all’interno dello stesso blocco possono sempre comunicare tra di loro, e un processo con user number 0 può fare ogni cosa, ignorando tutta la protezione. A causa di ciò, un processo con user number 0 è chiamato processo superuser.
Lasciando a tutti i processi nello stesso blocco la possibilità di comunicare indipendentemente dal loro user number, ci sarà un percorso di comunicazione ben controllato tra i processi comunicanti. Allo stesso tempo sarà possibile per due processi in due blocchi diversi comunicare tra di loro, e ancora essere in grado di comunicare con tutti gli altri processi nel loro blocco.

Figura 5.14. Si noti come tutti i processi nel blocco A del target 2 possono comunicare tra di loro anche se hanno diversi user number.
Supervisor vs. Superuser
Si noti che c’è una differenza tra un processo eseguito in supervisor mode e un processo assegnato al superuser number. Il primo non ha necessariamente 0 come user number ( che è il criterio per essere un processo superuser ) e viceversa. Il supervisor mode è CPU-dependent, ed è solitamente riservato al sistema operativo. E’ abbastanza comune, per esempio, che la capacità di cambiare il registro di stato della CPU la si abbia soltanto quando si è in supervisor mode.
E’ molto importante ottenere informazioni sull’uso scorretto del sistema operativo il prima possibile nella fase di sviluppo di un’applicazione.
A questo scopo OSE ha la capacità di fare un controllo errori estensivo. Sotto vi sono alcuni esempi di quali controlli vengono fatti quando si usa il meccanismo di controllo degli errori. La lista non è completa ma dovrebbe essere sufficiente per capire l’utilità di tale meccanismo.
Controlli sui parametri
Quando si alloca un buffer di segnale viene fatto un controllo per verificare che l’utente abbia specificato una dimensione del buffer che è possibile ottenere dai pool chiamanti.
Quando si passa l’identità di un processo ad una chiamata di sistema viene fatta una validazione dell’identità del processo passata.
Validare il chiamante
Un certo numero di chiamate di sistema sono controllate in modo che non siano chiamate da un processo interrupt o timer-interrupt.
Controlli sul buffer e lo stack
I puntatori del buffer sono controllati in modo che siano validi durante l’esecuzione di un certo numero di chiamate di sistema.
Il proprietario del segnale viene anch’esso controllato.
I buffer e gli stack avranno un endmark che permetterà a diverse chiamate di sistema di scoprire se un buffer o uno stack è stato sovrascritto al di la della sua lunghezza.
Controlli sull’inizializzazione
Quando viene fatta un’operazione sui semafori viene fatto un controllo per verificare se il semaforo è stato correttamente inizializzato.
Gestione degli errori
Un gestore degli errori permette ad un’applicazione di prendere conoscenza di eventi erronei run-time. Dopo che si è verificato un errore è compito del gestore dell’errore decidere se il sistema può recuperare dall’errore o se deve essere fatto ripartire.
Se non è presente un gestore degli errori definito dall’utente, quando un errore si presenta il sistema sarà fermato.
Ci sono alcuni processi interni in un sistema OSE che sono tutti chiamati processi di sistema.
Alcuni di essi possono non far parte di tutti i sistemi OSE, ma può essere utile sapere della loro esistenza perché essi appariranno nel debugger di sistema quando tutti i processi sono elencati.
E’ molto importante che tutte le chiamate di sistema in un sistema real-time ritornino il prima possibile.
Alcune delle chiamate di sistema in OSE che consumano più tempo ( come uccidere un blocco o un processo ) ritorneranno quindi prima che abbiano effettivamente completato tutto il loro lavoro. Tuttavia, dal punto di vista dell’applicazione, sembra che tutto il lavoro sia stato fatto quando la chiamata di sistema ritorna.
Un processo demone di sistema viene quindi usato per spostare il resto del lavoro mancante a un più ragionevole livello di priorità.
Come esempio, possiamo menzionare che una chiamata di sistema kill proc non fa altro che rimuovere il processo ( o i processi ) in questione dalle tabelle di sistema e invoca il demone di sistema prima di ritornare.
5.6.2 Demone di ricerca (hunt deamon)
Il demone di ricerca è un processo che amministra le richieste di ricerca in un singolo sistema target o in una rete di sistemi target. Il meccanismo di ricerca viene descritto più avanti nella parte sui link handlers. Quando un nuovo processo viene creato il demone di ricerca controlla se ci sono alcune richieste di ricerca pendenti riguardanti il nuovo processo. Se ci sono, il numero di identità del processo appena creato viene spedito in un segnale al processo che ha invocato la chiamata di sistema di ricerca.
Se il processo appena creato è un link handler e il percorso per il processo richiesto contiene il nome del link handler, allora la richiesta di ricerca viene passata al link handler e nessun segnale verrà a questo punto spedito indietro al processo richiedente. Questo rende possibile propagare una richiesta di ricerca in una rete di sistemi target dove i link handler non sono stati ancora creati. Non appena il link handler specificato dal percorso di ricerca può verificare l'esistenza del processo richiesto, un segnale verrà spedito indietro al processo richiedente.
Se un processo viene ucciso il demone di ricerca scarica ogni richiesta di ricerca pendente invocata per o da quel processo.
La chiamata di sistema tick avanza il tick counter di sistema e dovrebbe sempre essere eseguita sul livello di interrupt. Se per qualche ragione il chiamante non è un processo interrupt, allora il tick deamon, un processo interrupt special purpose, è invocato per fare il lavoro.
5.6.4 Local Debugger Module (LDM)
L’LDM è un singolo processo che fornisce a tutto il sistema funzioni di debug che si richiede risiedano nel target. L’uso di un processo LDM insieme ad un link handler rende possibile ad un sistema debugger esterno di comunicare con il kernel. L’LDM è richiesto soltanto quando il kernel è configurato per un livello di debugger maggiore di zero.
5.7 MODALITA’ DI PARTENZA DEL SISTEMA
Quando il sistema parte, una delle seguenti modalità di partenza può essere selezionata attraverso l’uso degli handlers. Bisogna ricordare che mentre il kernel real-time riconosce tutte e tre le modalità di partenza, il soft kernel riconosce soltanto la modalità cold start.
5.7.1 Cold Start
OSE entra in questa modalità di partenza in risposta ad un reset hardware, o in una situazione in cui si può assumere che la memoria non contenga informazione utile. Il kernel non tenterà di esaminare alcun dato condiviso dal momento che ciò potrebbe causare errori di parità o problemi simili. L’intero pool di sistema verrà vuotato, tutte le variabili interne del kernel inizializzate, e il sistema sarà quindi fatto partire. Le variabili del debugger, incluso il trace buffer, saranno perse. Infine tutti i processi statici saranno creati.
5.7.2 Warm Start
Se un handler warm start scritto dall’utente non forza una cold start, il kernel tenta di recuperare l’informazione del debugger precedentemente salvata dalla memoria. Se non è trovata informazione utile, verrà eseguita una cold start. Se i parametri di sistema sono ancora validi, essi sono reimmagazzinati per un uso successivo, e tutti i processi statici sono creati.
La modalità warm start è presente per permettere al system debugger per recuperare il setup interno.
5.7.3 Hot Start
Questa modalità di partenza del sistema è abilitata da una precedente chiamata di sistema power-fail. Questa chiamata di sistema chiamerà un power off handler scritto dall’utente, il cui scopo è di salvare lo stato interno del sistema e di chiudere il sistema entrando in un ciclo infinito, in modo tale che il kernel con l’aiuto di un power on handler possa decidere se possa eseguire una hot start al prossimo reset. Se è così, il kernel immediatamente caricherà ( swap in ) i processi background o prioritizzati in esecuzione più recentemente. Ciò essenzialmente significa che il sistema continuerà ad eseguire nello stato in cui si trovava quando la chiamata power_fail fu invocata.
Un sistema OSE può essere visto come una grande applicazione indipendentemente dal fatto che risieda in un singolo target o sia distribuito su diversi sistemi target. Qui discuteremo i meccanismi usati in OSE per comunicare con differenti parti di un’applicazione che possono risiedere in differenti target. Gli stessi meccanismi sono anche usati per comunicare con altri membri della famiglia OSE, come il system debugger.
Ogni kernel OSE è in grado di comunicare con altri kernel OSE. Dal momento che un sistema OSE può essere costituito da una rete di target, è quindi importante ricordarsi che ci deve sempre essere un kernel separato eseguito in ogni CPU nel sistema target, e che non è possibile per un kernel fare uso di più di una CPU.
Questo rende una rete OSE lascamente connessa ( loosely coupled ), e in molti casi un sistema fault-tolerant.
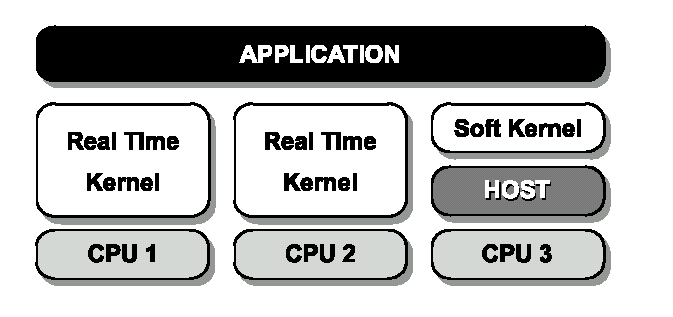
Figura 5.15. Una applicazione OSE può essere distribuita su diverse CPU fisiche, usando sia kernel real-time embedded sia soft kernel host based.
Sistemi loosely coupled e fault-tolerant
In un sistema OSE multi-CPU, la comunicazione fra processi residenti in differenti target-CPU viene fatta spedendo segnali, non condividendo aree di dati.
Questo rende il sistema più fault-tolerant, dal momento che se la memoria è rovinata in un sistema di memoria condivisa, questo potrebbe influenzare la funzionalità di tutte le CPU che fanno uso di quella memoria. Se invece si verifica un errore in un sottosistema in una rete di sistemi completamente separati, soltanto quel sottosistema ne sarà affetto. Quel sottosistema difettoso può quindi essere rimpiazzato da uno nuovo, correttamente funzionante. Dal momento che tutti i processi comunicanti con il sottosistema difettoso saranno informati quando quel sottosistema è stato rimosso, essi ricercheranno la nuova copia del processo nel nuovo, corretto sistema. Quando il nuovo sottosistema è in esecuzione, l’applicazione distribuita continuerà quindi normalmente.
Si noti che affinchè un processo prenda informazioni sulla morte o la rimozione di un altro processo, deve essere invocato un attach a quel processo. Questo meccanismo verrà descritto più avanti.
Se ci deve essere comunicazione tra processi in differenti sistemi target, dovrà esserci un processo link handler presente in ogni target coinvolto. Lo scopo del link handler è quello di gestire i canali logici tra processi in target separati.
Un link handler deve rispondere a una richiesta di ricerca e creare un processo fantasma che viene usato per stabilire un canale logico trasparente. Anche se il link handler ha lo scopo principale di fornire un’interfaccia di rete inter-target, può anche essere usato per fornire un’interfaccia verso un file system o qualche altra applicazione che deve comportarsi in modo difensivo verso i clienti.
Un link handler ben scritto deve tener presenti un numero di importanti punti nella comunicazione con altri sistemi target, quali le convenzioni sui nomi, l’ordinamento dei byte, la supervisione del canale, la conversione dei dati, la creazione e la distruzione di processi fantasma. E’ compito del progettista hardware decidere quale device driver fisico usare, sia esso un bus, un canale RS232, un link UDP, ecc.
L’applicazione non ha bisogno di conoscere ciò perché il concetto di link handler è totalmente trasparente. Un processo semplicemente spedisce un segnale ad un altro processo indipendentemente dal fatto che sia coinvolto o no un link handler.
Comunicare attraverso link handlers può comportare una serie di passi differenti a seconda del livello di sicurezza desiderato del canale logico.
I vari passi sono descritti sotto:
Un processo che vuole comunicare con un altro processo deve prima ricercare quel processo invocando una chiamata di sistema hunt. L’indirizzamento del processo desiderato viene fatto presentando il percorso di ricerca dal processo di partenza al processo richiesto.
Quando il processo desiderato risiede in un target diverso, è necessario coinvolgere un certo link handler. E’ responsabilità di quel link handler stabilire un canale logico al processo desiderato, il che viene fatto creando un processo fantasma nel target dell’hunter.
Il processo fantasma quindi si comporta come un’immagine del processo richiesto nell’altro target e non sarà creato fino a che il processo desiderato non è stato trovato nell’altro target.
Dopo che il processo fantasma è stato creato, il processo che ha invocato la ricerca sarà informato dell’esistenza del processo richiesto. Il meccanismo fantasma verrà descritto più in dettaglio più avanti.
Il modo più sicuro per far comunicare due processi, A e B, è di permettere al processo A di specificare un segnale da attaccare al processo B, e viceversa. In questo modo il processo A riceverà il segnale specificato se qualcosa accade al processo B. Esso riceverà il segnale anche se qualcosa accade al canale logico tra i due processi comunicanti. Lo stesso vale per il processo B. Ricevendo il segnale attaccato un processo acquisisce informazioni su qualche fallimento nella comunicazione , e può prendere i provvedimenti appropriati, come invocare una nuova richiesta di ricerca.
I processi possono ora cominciare a scambiarsi segnali fino a che uno dei processi viene ucciso, o fino a che un’ulteriore comunicazione non è più desiderata. Se un processo viene ucciso, deliberatamente o per qualche altra ragione, l’altro processo non riceve nessuna informazione di ciò se non ha attaccato un segnale al processo ucciso. Ciò è abbastanza spiacevole dal momento che un processo può spedire un segnale a un processo che non esiste più senza conoscere la sua assenza, e poiché il kernel non sarà in grado di trovare il processo destinazione esso butterà via il segnale.
Se un segnale è attaccato a un processo che muore, tale segnale verrà spedito indietro al processo che ha invocato l’attach. Quando quel processo riceve il segnale attaccato, interpreterà il segnale come un avviso di qualche errore nel suo canale logico verso il processo appena morto. In questo modo il processo di attach può ripartire dall’inizio di nuovo invocando una nuova ricerca. Si noti che il successo della nuova richiesta di ricerca dipende dal fatto che qualche funzionalità nel sistema target dove l’errore è avvenuto abbia o no realizzato qualche forma di recupero dall’errore.
Una chiamata di sistema detach è soltanto un modo di dire al kernel che non c’è più bisogno di sapere se qualcosa accade al canale o al processo attaccato. Può essere usata, per esempio, prima di cancellare deliberatamente uno dei due processi comunicanti in un canale logico. Se non viene fatto alcun detach prima di uccidere il processo il programmatore dell’applicazione deve mettersi al corrente se il segnale che notifica l’improvvisa morte del processo è dovuto a un’uccisione deliberata che può essere ignorata, o a qualche errore di stato di cui ci si dovrebbe occupare. D’altra parte, un tale segnale potrebbe essere usato come un acknowledgement dell’uscita con successo della chiamata di sistema kill_proc.
5.8.3 Processi fantasma e canali logici
Per rendere la comunicazione tra processi non residenti nello stesso target la più trasparente possibile, OSE introduce i processi fantasma. L’uso dei processi fantasma rende possibile la costruzione di canali di comunicazione logici.
Supponiamo che il processo P1 voglia comunicare con il processo P2, che risiede in un altro sistema target. Deve essere stabilito un qualche tipo di collegamento. Questo viene fatto nei due passi seguenti:
Quando questi due passi sono stati compiuti, i processi P1 e P2 saranno in grado di comunicare tra di loro esattamente come se si trovassero nello stesso target.
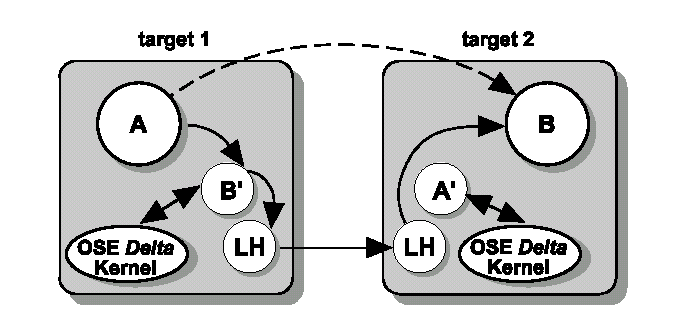
Figura 5.16. Anche se il canale di comunicazione tra il processo A in un target e il processo B in un altro coinvolge i processi fantasma A’ e B’ e i link handlers, il canale di comunicazione appare come se fosse tra due processi nello stesso target. Questo canale logico è illustrato con la linea tratteggiata.
La catena dei due processi fantasma e dei due link handlers forma un cosiddetto canale logico tra i due processi. Usando questo concetto, la comunicazione inter-target sarà tanto semplice quanto la comunicazione fra processi residenti nello stesso target. Anche le stesse chiamate di sistema possono essere usate per la comunicazione fra processi sia che i processi comunicanti risiedano nello stesso target oppure no.
Ciascun processo che vuole stabilire una connessione con un altro processo in qualche target deve prima ricercare quel processo. Se esso è trovato, il processo di partenza si attaccherà a quel processo. Se qualcosa accade al link o uno dei processi comunicanti muore, il processo fantasma verrà rimosso e il kernel informerà il processo (o i processi ) attaccato che la connessione è stata rotta.
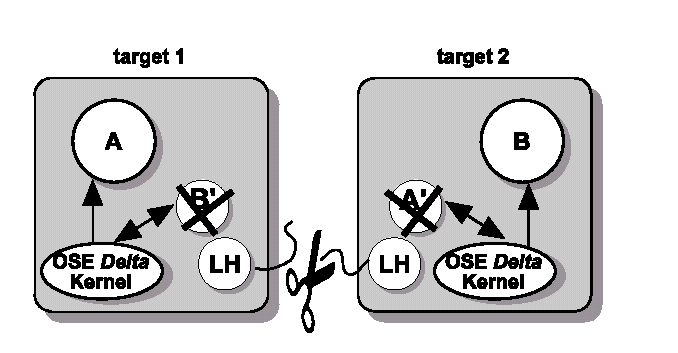
Figura 5.17. Se la comunicazione fisica fra due target fallisce, i kernel in ciascun target rimuoveranno i processi fantasma appartenenti alla linea di comunicazione fallita e notificheranno a tutte le parti coinvolte il malfunzionamento.
La prima volta che un processo remoto in un altro target viene ricercato, potrebbe passare un po’ di tempo prima che venga trovato e il canale logico stabilito. Tutte le successive richieste di ricerca saranno invece molto più veloci, visto che ora è come se il processo richiesto fosse locale al sistema target.
Non è necessario ricercare e attaccarsi ad un processo prima di comunicare con esso se entrambi i processi comunicanti sono nello stesso sistema target.
5.8.4 Chiamate di sistema remoto
Un certo numero di chiamate di sistema in OSE possono operare su processi e blocchi collocati in altri sistemi target. Queste chiamate di sistema saranno tutte internamente tradotte dal kernel in chiamate di sistema remoto. Le chiamate di sistema remoto sono transazioni di segnali eseguite dal kernel in risposta a chiamate di sistema che specificano un processo ( solitamente un processo fantasma ) con un call server remoto attaccato.
Per prima cosa, il kernel individua il processo call server remoto e spedisce ad esso un segnale remote_call. Quindi il call server remoto ( che è spesso anche un link handler ) propaga la chiamata di sistema richiesta al sistema target remoto. Il call server remoto ritorna una risposta con il segnale remote_response, o con il segnale remote_cancel se il call server remoto non può eseguire la chiamata di sistema remoto.
Un call server remoto è generalmente un link handler che fornisce un servizio esteso.
Quasi tutti i server remoti sono anche link handlers che forniscono l’interfaccia di rete.