
Capitolo 3: Kernels Real-Time e Sistemi Run-Time
3.1 SISTEMI RUN-TIME CHE SUPPORTANO ADA
3.2 PROGRAMMI REAL-TIME AD ALTE PRESTAZIONI E PREDICIBILI
3.3 PREDICIBILITA' NEI SISTEMI RISC: VxWorks e pSOS.
3.4 GEM: ALTA PERFORMANCE PER APPLICAZIONI REAL-TIME PARALLELE
3.6 YARTOS: ALTA PERFORMANCE E PREDICIBILITA' PER APPLICAZIONI MULTIMEDIALI
3.7 I KERNELS REAL-TIME C-EXECUTIVE e PSX
Figura 3.1. Strati del sistema: il kernel è il primo strato di software che si trova sopra all'hardware
Le ricerche sui sistemi operativi real-time negli Stati Uniti sono state guidate da tre questioni primarie:
Inoltre la ricerca recente si sta interessando sulla possibilità di fornire una certa piattaforma su cui diversi sistemi real-time possono essere costruiti ( per es. thread e micro-kernel configurabili e real-time).
I sistemi commerciali, d'altro canto, hanno tipicamente fornito o supporto Ada ( ad es. ambienti supportati da Honeywell o TRW), o un insieme fisso di primitive (micro-kernel) al livello del processo(ad es. pSOS), o si sono focalizzati nella costruzione di estensioni real-time di Unix. Quest'ultimo approccio fornisce gli standard real-time POSIX. Inoltre è stata anche sviluppata una versione real-time del sistema operativo Mach.
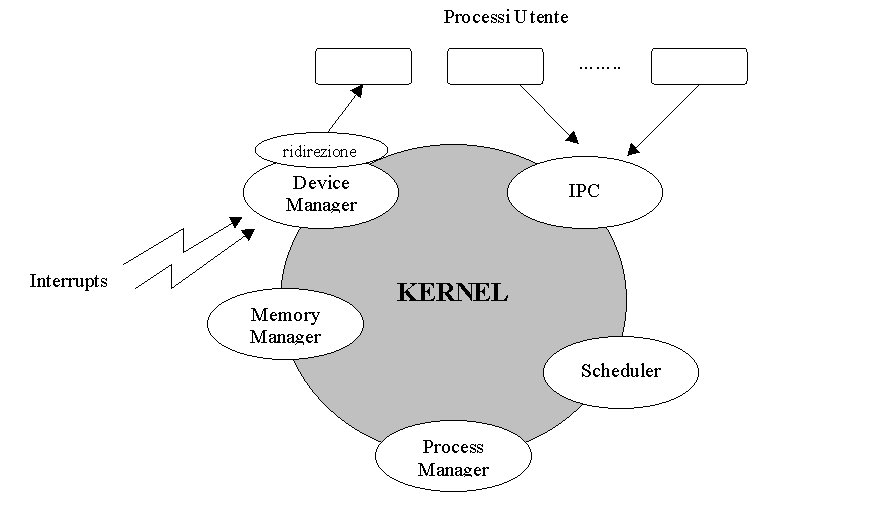
Figura 3.2. La struttura generale del kernel.
3.1 SISTEMI RUN-TIME CHE SUPPORTANO ADA
Ada 9X è una revisione del linguaggio di programmazione Ada studiato per adattarsi alle esigenze hard real-time.
Corset e Lace sono interfacce runtime. Corset è una specifica di interfaccia per un ambiente di supporto runtime compatto per task Ada.
Task e programmi Ada richiedono servizi Corset e Lace attraverso normali chiamate di procedure Ada.
Corset nasconde i dettagli dell'ambiente di supporto runtime (RSE) al compilatore. Lace, a sua volta, nasconde i dettagli dell'allocazione del processore all'Ada RSE. Questo permette di adattare la politica di dispatching alla particolare applicazione.
Inoltre Lace supporta la multiprogrammazione di semplici procedure Ada senza il coinvolgimento dell'Ada RSE, in tal modo eliminando inefficienze e impredicibilità non necessarie. Tali procedure multiprogrammate possono essere eseguite simultaneamente da altri task che fanno uso dell'Ada RSE. Perciò è facile costruire sistemi ibridi. La temporizzazione dell'esecuzione rimane sotto il controllo del dispatcher Lace. Lace non provvede direttamente alla comunicazione intertask o alla gestione della memoria. Tali servizi sono forniti separatamente, possibilmente usando le operazioni Lace.
3.2 PROGRAMMI REAL-TIME AD ALTE PRESTAZIONI E PREDICIBILI
Caratteristiche basilari di molti sistemi operativi real-time o kernel di sistemi operativi sono:
Sfortunatamente, molte tecniche di ottimizzazione che aumentano la performance nei sistemi non real-time riducono la predicibilità temporale e devono quindi o essere eliminate oppure scarsamente usate nei sistemi operativi real-time. Esempi di quanto detto possono essere la memoria cache e la memoria virtuale, le code FIFO, il pipelining delle istruzioni e i ritardi associati ai lock. Quando tali tecniche sono usate nei sistemi real-time, la predicibilità del sistema deve essere esplicitamente preservata separando il codice temporalmente critico dal restante codice applicativo. L'idea base delle tecniche a strati è che uno strato più alto può essere implementato in modo da essere predicibile se tutti gli strati più bassi sono predicibili. Specificamente, una volta che si conoscono i tempi di computazione nel caso peggiore degli strati inferiori, si possono calcolare i tempi di computazione nel caso peggiore degli strati superiori.
Vedremo ora la struttura di alcuni kernel real-time, illustrando le tecniche in essi usate per ottenere un'esecuzione real-time efficiente e predicibile.
3.3 PREDICIBILITA' NEI SISTEMI RISC: VxWorks e pSOS.
Mentre le architetture RISC aumentano i tassi di esecuzione medi (attraverso il pipelining delle istruzioni, con l'uso delle cache, usando speciali co-processori floating-point on-board, usando tecniche di latency-hiding nelle operazioni di memoria o grandi insiemi di registri), esse d'altro canto introducono incertezze nei tempi di esecuzione delle istruzioni. Previsioni scorrette possono manifestarsi nel flusso delle pipeline (i processori RISC spesso hanno diverse pipeline, ciascuna con diversi stadi). Ciò porta a dei ritardi per il fatto che la cache dell'istruzione deve essere riempita. Inoltre, possono sorgere conflitti sui registri se identiche risorse sono richieste da istruzioni presenti insieme in una pipeline. In modo similare, mentre le finestre di registri accelerano l'invocazione delle subroutine, salvare tutte la finestre quando si verifica un cambiamento di contesto può consumare un certo tempo.
In più, dettagli di basso livello come i tempi di esecuzione delle istruzioni ( e di qui, il tempo di esecuzione nel caso peggiore di un segmento di codice) cambiano ad ogni implementazione di un'architettura. Alcuni di questi problemi sono affrontati dai sistemi operativi VxWorks e pSOS che ora discuteremo.
VxWorks. Il sistema operativo real-time VxWorks affronta gli overhead connessi ad un cambiamento di contesto salvando solo quelle finestre di registri (su una Sparc) che sono attualmente in uso (come indicato dal bit window invalid mask (WIM)) da parte di un task che sta per essere cambiato di contesto. Quando il contesto del task è ripristinato, solo una singola finestra di registri deve essere ripristinata (il suo contenuto è ripristinato dalla memoria, e il suo WIM è settato). Le altre finestre sono ripristinate più tardi all'appropriato ritorno da subroutine ( il trap di underflow della finestra fa si che il contenuto venga ripristinato). VxWorks permette anche alle finestre di registri (tipicamente ci sono diverse di tali finestre nelle implementazioni Sparc) di essere usate come 'register-caches', per cui una finestra è salvata durante un cambiamento di contesto solo se caricare il nuovo contesto lo richiede. Questo ha il vantaggio di eliminare il tempo per salvare e ripristinare le finestre di registri se il task uscente gira di nuovo presto, e se il numero di finestre di registri usate da ciascun task è piccolo. VxWorks permette anche a un insieme di finestre di registri di essere allocate a un task in modo 'dedicato': queste particolari finestre non richiedono di essere salvate quando il task 'esce'.
Dal momento che l'interrupt-processing è spesso un task ad alta priorità, VxWorks permette al progettista dell'applicazione di riservare una o più finestre di registri a questo scopo. In tal caso, gli interrupt non richiedono di ripristinare alcuna finestra di registri per commutare nel contesto del gestore dell'interrupt, a meno che il livello di annidamento degli interrupt non diventi troppo grande.
pSOS. Il sistema operativo pSOS offre blocchi costruttivi 'standard' per sistemi operativi real-time (ad es. kernels, debuggers, monitors, ecc. ) su diverse piattaforme hardware.
E' visto come un 'sistema operativo plug-in' che può essere prontamente usato da implementatori di software real-time. pSOS è binario position-independent in cui al 'software di sistema' viene fatto accesso attraverso traps, e le proprietà temporali di tutte queste chiamate di sistema sono definite e garantite dal sistema (come da specifica di progetto del sistema).
pSOS+ è il kernel di un sistema operativo real-time per progetti embedded, ed è un superset di pSOS. pSOS+ partiziona l'attività del sistema in un certo numero di task distinti, che logicamente vengono eseguiti in parallelo. I task sono schedulati usando uno scheduling preemptive basato su priorità, con 255 livelli di priorità. Le priorità dei task possono essere cambiate dinamicamente. Esistono quattro primitive di inter-task communication. Un task 'ricevente' può bloccarsi su un singolo evento di flag o una combinazione booleana di tali flag. Sono disponibili semafori di sistema 'di conteggio' (counting semaphores) per la mutua esclusione. E' possibile specificare un timeout con un semaforo. I semafori sono dinamicamente creati e distrutti. I task in attesa su un semaforo distrutto sono resi pronti, e viene ritornata una condizione di errore. PSOS+ fornisce anche code globali di messaggi. Ciascun pacchetto può essere grande fino a quattro parole. Infine, i task possono interagire usando segnali tipo Unix.
pSOS+ supporta sia multiprocessori strettamente accoppiati che lascamente accoppiati. La funzionalità della versione multiprocessore di pSOS+, chiamata pSOS+m, è divisa in due strati: lo strato Kernel Interface (KI), gestisce tutta la comunicazione inter-processore generata dal kernel pSOS+m, mentre lo strato pSOS+m gestisce le attività dei task, la comunicazione inter-task e le routine di servizio degli interrupt all'interno di un singolo processore. Sono attualmente supportati due tipi di KI: uno basato sulla comunicazione tra processori a memoria condivisa, l'altro basato sul TCP/IP.
3.4 GEM: ALTA PERFORMANCE PER APPLICAZIONI REAL-TIME PARALLELE
GEM è l'acronimo di Generalized Executive for real-time Multiprocessors applications. Esso soddisfa diversi requisiti del software real-time. Fu costruito per un'architettura target embedded costituita di multiprocessori in rete, e fu valutata con il software di controllo di un robot camminatore semiautonomo, la walking machine ASV.
I contributi primari del sistema GEM sono:
Inoltre, GEM iniziò la ricerca che si occupa di applicazioni real-time altamente dinamiche, offrendo semplici meccanismi per un adattamento on-line del programma in risposta a variazioni nella configurazione hardware e alle esigenze di performance o affidabilità dell'applicazione.
Processi e scheduling. La coesistenza di attività multiple, lascamente interagenti, più ampie nelle applicazioni di robotica (ad es. pianificazione di un percorso) con attività strettamente interagenti, più piccole (ad es. servo-comando ) motiva il supporto di due differenti dimensioni di attività in GEM: processi e micro-processi.
Un processo GEM può essere schedulato per l'esecuzione ad un costo, in termini di tempo, moderato e, tipicamente, interagisce lascamente con altri processi. Per la rappresentazione di attività che sono attivate frequentemente e interagiscono strettamente tra loro, un programmatore può selezionare un micro-processo GEM (più simile ad un thread nei sistemi successivi), che è un'attività di controllo separabile all'interno di un singolo processo GEM. Può interagire con altri micro-processi nello stesso o in un diverso processo, e può essere attivato ad un basso costo in termini di tempo. I costrutti di scheduling dei processi includono una ricca varietà di chiamate di sistema esplicite per gestire sia processi periodici sia processi sporadici sia microprocessi che girano a tassi di esecuzione diversi, incluso mettere dei processi in attesa, risvegliarli, controllare i timer di sistema usati per schedulare i processi, ecc. I microprocessi sono schedulati usando un costrutto di comunicazione chiamato operazione 'Poke', che permette a un micro-processo in attesa su una porta di input specifica di essere attivato con un overhead molto basso.
Comunicazione. GEM offre un meccanismo di comunicazione basato sulle mailbox accoppiato con buffers di comunicazione esplicitamente riservati e gestiti per supportare tre differenti modelli di comunicazione usati nelle applicazioni real-time. Il primo modello supporta l'esecuzione di processi asincroni con perdita di dati. In questo modello, i task generano output continuamente basati sui loro input, che si assume siano sempre presenti. Le comunicazioni tra task possono occasionalmente andare perse, ma i task operano correttamente fintantochè i loro input non sono invecchiati oltre delle tolleranze staticamente definite note al programmatore applicativo (ad es. processing di input da un sensore).
Il secondo modello supporta l'esecuzione di processi sincroni senza perdita di dati, dove i task vengono eseguiti in modo sincrono e la loro esecuzione è guidata dall'accettazione di singoli elementi di input l'uno dall'altro (ad es. una ricezione di una richiesta di servizio e dei suoi parametri), che si assume non siano sempre presenti. Input e output non possono essere persi senza mettere in pericolo la correttezza dell'operazione di sistema.
Il terzo modello supporta l'operazione sincrona o asincrona di processi con possibile perdita di dati vecchi. E' un ibrido dei modelli 1 e 2 che assume che un insieme di dimensioni fisse di recenti elementi di output di un task sia disponibile come input ad altri task (ad es. è utile per il logging dei dati ).
Una valutazione estensiva del sistema e misure della performance dimostrano l'importanza delle varie funzionalità offerte da GEM così come le significative implicazioni sulla performance di scelte di progetto e implementative fatte dagli implementatori applicativi e del sistema operativo quando costruiscono software real-time. Il termine operating software è stato coniato per dare un'idea dello stretto accoppiamento tra sistema operativo real-time e codice applicativo.
Scheduling multiprocessore. In contrasto con altre ricerche nei sistemi real-time, le politiche e i meccanismi di scheduling di più alto livello sviluppati per GEM si indirizzano sulle applicazioni real-time dinamiche esemplificate dal software operativo del veicolo ASV, in cui i task possono apparire durante l'esecuzione del sistema, con vincoli temporali non noti al momento dell'inizio del programma. Lo scheduling, allora, deve occuparsi sia dell'assegnamento o mappaggio dei task ai processori sia del loro scheduling su un singolo processore.
Gli scopi del progetto Spring includono: lo sviluppo di algoritmi di real-time scheduling dinamici, distribuiti, online; il supporto di una rete di multiprocessori; lo sviluppo di nodi multiprocessore per supportare direttamente il kernel e lo sviluppo di tools real-time. Il sistema Spring è fisicamente composto da una rete di multiprocessori, uno dei quali è stato costruito come 'banco di prova'. Ciascun multiprocessore contiene almeno un processore applicativo, uno o più processori di sistema e un sottosistema di I/O.
I task periodici o non periodici sono tracce di esecuzione attraverso programmi, e sono le entità distribuibili nel sistema. I task non periodici hanno deadline, e i task periodici hanno inizializzazioni ricorrenti e deadline finchè terminano. I task di sistema girano sui processori di sistema, e i task applicativi possono girare sia sui processori applicativi sia sui processori di sistema riservando esplicitamente tempo sui processori di sistema.
Inoltre, il kernel contiene primitive di gestione dei task che utilizzano la nozione di preallocazione laddove possibile per aumentare la velocità e eliminare ritardi impredicibili.
Il sottosistema di I/O è un'entità separata dal kernel Spring. Esso gestisce I/O non critico, lenti dispositivi di I/O, e veloci sensori. Il sottosistema di I/O può essere controllato da qualche altro kernel real-time, se necessario.
Il progetto del kernel Spring è basato sul principio della segmentazione e riflessione come applicato ai sistemi hard real-time. La segmentazione è il processo di dividere le risorse dei sistemi in unità dove la dimensione delle unità è basata su vari criteri particolari rispetto alle risorse in considerazione e ai requisiti applicativi. L'idea base nell'usare la segmentazione nei sistemi hard real-time è di avere unità ben definite di ciascuna risorsa, per aumentare la comprensibilità e per permettere agli algoritmi online di collegare esplicitamente unità ben definite di ciascuna risorsa in modo da raggiungere la predicibilità nel rispetto dei vincoli temporali. La riflessione significa che il sistema è in grado di ragionare sul proprio stato e sullo stato dell'ambiente nel definire le proprie azioni. Ciò viene richiesto ai sistemi che operano in ambienti altamente dinamici.
Scheduling
Gli scheduler di Spring sono composti di quattro moduli. Come nella gran parte dei sistemi operativi, il modulo di più basso livello è un dispatcher processor-resident, il quale semplicemente rimuove il prossimo task da una task table di sistema globale (STT) contenente tutti i task garantiti. I task in questa tabella sono già ordinati nel giusto ordine per i multipli processori applicativi. Il secondo modulo è uno scheduler locale, uno per processore. Esso è responsabile di garantire localmente che un nuovo task possa fare la sua deadline, e di ordinare i task specifici del processore nella STT.
Il terzo modulo è lo scheduler globale, che tenta di trovare un posto per l'esecuzione di ogni task che non può essere garantito localmente. L'ultimo modulo è un Meta Level Controller, che può adattare vari parametri quando rileva cambiamenti significativi nell'ambiente, e può servire come interfaccia d'utente del sistema
Gestione della memoria
Nel kernel Spring, il Sistema Operativo è core-resident. Per eliminare ampi e imprevedibili ritardi dovuti alla allocazione dinamica della memoria (page fault e page replacements), il kernel Spring pre-alloca un numero fisso di istanze di qualcuna delle strutture dati del kernel (blocchi di controllo dei task, stack, buffers, ecc.), e i task sono accettati dinamicamente se le strutture dati necessarie sono disponibili.
Inter-Process Communication
Il kernel Spring supporta la sincronizzazione e la comunicazione con cinque primitive di IPC: SEND, RECV, SENDW (send and wait), RECVW (receive and wait), CREATMB (create mailbox). Le mailbox sono oggetti della memoria. Il kernel Spring evita l'uso dei semafori implementando la mutua esclusione direttamente come parte del task schedule.
3.6 YARTOS: ALTA PERFORMANCE E PREDICIBILITA' PER APPLICAZIONI MULTIMEDIALI
YARTOS (Yet Another Real Time Operating System) è un kernel di sistema operativo che supporta la costruzione di applicazioni real-time efficienti e predicibili. Il modello di programmazione supportato da Yartos è un'estensione della disciplina di Wirth della programmazione real-time. E' un sistema di passaggio dei messaggi con una semantica della comunicazione tra processi che specifica la risposta real-time che un sistema operativo deve fornire al ricevente. Questa semantica fornisce una struttura sia per esprimere computazioni processor-time dependent sia per specificare il comportamento real-time dei programmi.
YARTOS supporta due astrazioni di base: task e risorse. Un task è un thread di controllo indipendente che è invocato a intervalli sporadici. Gli intervalli di invocazione e le deadline per un task sono derivati da costrutti nel modello di programmazione di alto livello. Durante l'esecuzione, un task accede a un certo numero di risorse. Una risorsa è un oggetto software che incapsula dati condivisi ed esporta un'insieme di procedure per l'accesso e la manipolazione dei dati. Questi oggetti richiedono un accesso mutuamente esclusivo alle risorse che essi incapsulano. Un insieme di task viene detto fattibile se tutte le richieste di tutti i task completeranno l'esecuzione prima delle loro deadline e a nessuna risorsa condivisa è fatto accesso simultaneamente da più di un task.
L'algoritmo di sequencing per i task è una variazione del ben noto earliest deadline first (EDF). E' un algoritmo di scheduling preemptive priority-driven con assegnamento di priorità dinamico. La caratteristica originale dell'algoritmo è la sua manipolazione dinamica delle deadline delle invocazioni dei task per assicurare che i task mantengano un accesso esclusivo a qualunque risorsa condivisa a cui possano fare accesso. Questa manipolazione delle deadline assicura che non ci saranno contese per risorse condivise a run-time. Di qui, YARTOS non deve fornire alcuna speciale facility di locking sulle risorse condivise. Poiché in YARTOS i task vengono eseguiti fino al completamento, tutti i task sono eseguiti su un singolo stack run-time. Ciò migliora l'utilizzazione della memoria e riduce l'overhead associato al cambiamento di contesto. YARTOS è stato usato per supportare un'applicazione di teleconferenza e un sistema di realtà virtuale.
3.7 I KERNELS REAL-TIME C-EXECUTIVE e PSX
Descrizione dei kernels. C-executive è un kernel di sistema operativo Real-time per lo sviluppo di applicazioni embedded, cui possono essere affiancate le funzionalità del kernel PSX. Il sistema formato si pone a metà strada tra un semplice kernel ed un sistema completo (UNIX per esempio). Le primitive dei kernel (chiamate di sistema), sono implementate quasi totalmente in linguaggio C e possono essere montate sul sistema Harware, secondo le effettive necessità, anche solo parzialmente. Il kernel ha dimensioni ridotte, è quindi possibile caricarlo in RAM o in PROM nonché compilare congiuntamente kernel ed applicazioni come un unico blocco.
Il sistema operativo permette la gestione di più processi concorrenti (multi-tasking), anche con configurazioni Hardware minime.
Risulta particolarmente adatto a prodotti di basso costo realizzati in grandi quantità. PSX aggiunge una parte dello standard POSIX.1 (134 chiamate di sistema), permette la gestione a singolo utente o singolo gruppo di processi o thread (fino a 32000).
Ambiente applicativo. C-executive è stato sviluppato a partire dai primi anni 80 e viene ora utilizzato su diversi supporti embedded, quali:
Avionica militare
Acquisizione dati di laboratorio
Monitors cardiaci
Terminali grafici
Controllori per stampanti (usato da 20 compagnie su 7 architetture)
Ricevitori GPS
Sistemi di comunicazione (PBX)
Sistemi per controllo di processo
Hardware e dimensioni del kernel. Il kernel C-executive è altamente scalabile poiché le chiamate di sistema vengono linkate da librerie C durante la messa in opera del sistema. Le dimensioni variano da un minimo di soli 4,5 Kbytes ad un massimo di 20 Kbytes (mediamente 12 Kbytes). Aggiungendo le funzionalità di PSX si occupano da 5 a 40 Kbytes.
Il sistema operativo può essere montato su diversi processori:
8086/80286, 80186/Am186EM (Real mode)
80386/486/Pentium, Am386EM, 80386EX, Am486, Am586, AMD K6 (protected mode)
Motorola 68000 fino a 68060, 683xx
Motorola ColdFire
Intel i960 (80960), i860
AMD 29000 fino a 29240
PowerPC(403GA, 603, 860/821/823)
R3000, R4000, R4200, R4300, R4600
ARM7, ARM7TDMI(Thumb), StrongARM
PA-RISC, Sun SPARC, NEC V810/830, Toshiba R3900, Zilog Z80, TI TMS320C30/31 e TMS34020
INMOS transputer T212, T222, T400, T425, T800, T801, T805.
Il sistema supporta molti dispositivi Hardware gestendo drivers specifici (scritti interamente in ANSI C) basati al 49 per cento su C-executive, al 49 per cento sul dispositivo ed il 2 per cento sul tipo di CPU usata.
Modello temporale. Il modello temporale può essere scelto tra il classico time driven e l'event driven. In quest'ultimo caso i passaggi di stato dei processi sono guidati da eventi esterni (gestiti dalle routine di interruzione corrispondenti).
Modello di esecuzione. C-executive propone una modellizzazione dei processi a flusso di dati. Il sistema è visto come un insieme di processi indipendenti ed asincroni, ognuno dei quali comunica con gli altri e con l'ambiente esterno tramite ben definiti flussi di dati (in ingresso ed uscita). L'interazione tra i processi può avvenire attraverso diversi meccanismi, quali: semafori, eventi, segnali, messaggi (leggendo e scrivendo code). È inoltre possibile una gestione time-based con ripetizione ciclica e temporizzata dei processi.
Le chiamate di sistema fornite da C-executive (sono 64) permettono di gestire processi:
createp, deletep, exit per creare, cancellare e terminare un processo,
suspend per sospenderlo, resume per riattivarlo,
syssleep sospende l'esecuzione per un intervallo di tempo,
nstart e pstart per mandare in schedulazione un processo (per nome o identificatore),
rawtime ottiene il tempo in unita di interruzioni del clock.
Altre chiamate permettono la gestione della priorità di processo, il livello di interruzione, l'ingresso in regioni critiche (anche su segnali). Si possono gestire terminali con lettura e scrittura di dati in modalità full e half duplex. La lettura e scrittura su dischi, terminali, code e socket è fatta utilizzando le stesse primitive (open, read e write). La comunicazione tra processi, l'I/O fisico e inter-processore diventa quindi molto simile dal punto di vista dei processi e si facilita l'implementazione di applicazioni distribuite.
PSX aggiunge 134 primitive per la gestione di threads, di singoli utenti, di gruppi di processi.
È possibile creare set di segnali associati ad un singolo processo, mascherare e testare singolarmente i segnali. Sono fornite primitive per una gestione più estesa del tempo, in particolare, conversioni per l'ora universale e ticks di sistema.
Il sistema non contiene direttamente un filesystem che è offerto separatamente come opzione (CE-DOSFILE).
Struttura del sistema operativo. Lo scheduling C-executive è basato su un algoritmo a priorità completamente preemptive, mentre differenti politiche di schedulazione possono essere implementate utilizzando le primitive fornite. È possibile cambiare dinamicamente la priorità dei processi in modo da adattare l'esecuzione ai vincoli imposti dall'ambiente esterno. Le primitive cycle e ncycle, che usano rispettivamente ID e nome del processo, permettono la schedulazione a tempi determinati (periodicamente) dei processi, fornendo una visione time driven dell'esecuzione.
La comunicazione tra processi può essere realizzata utilizzando quattro meccanismi: semafori, eventi, segnali e code di dati.
I semafori sono gestiti con primitive di lock, locktm (con time out) ed unlock che permettono di assegnare e rilasciare una risorsa al processo invocante. Le wlock e wlocktm (versione bloccante di tali primitive) permettono al processo di restare in attesa su una risorsa occupata.
La primitiva ewait (ewaittm con time out) permette ad un processo di restare in attesa di un determinato evento, mentre la ewakeup permette il risveglio dei processi in attesa su una lista d'eventi. Altre primitive permettono il settaggio e la lettura di flag associati agli eventi di sistema.
La primitiva kill è utilizzata per inviare un segnale ad un altro processo. Alcune primitive permettono l'ingresso e l'uscita in regioni critiche (entreg e lvreg), anche riferite a regioni critiche su segnali (entsig e lvsig). PSX aggiunge poi un insieme di primitive per la gestione di set di segnali e diversi tipi d'attesa da parte dei processi (attesa sincrona, asincrona, inibizione).
Le code di dati permettono lo scambio di messaggi di lunghezza generica tra processi. Tali code sono contenute in memoria e le loro caratteristiche possono essere modificate dinamicamente dai processi. Il kernel non si occupa direttamente dello scambio dei massaggi, come farebbe in caso di mailbox, ma solo della creazione e gestione del supporto (coda di dati) su cui i processi possono comunicare. Le primitive fornite ne consentono la creazione (create), l'apertura e chiusura (open e close), la lettura e scrittura (anche con timeout), il conteggio di caratteri e messaggi, ed il settaggio delle caratteristiche.
I terminali ed i dispositivi di I/O sono gestiti allo stesso modo dei files, è permessa la loro apertura (open) e chiusura (close), la scrittura e lettura di dati, il settaggio del tipo di trasmissione, ecc.
Funzionalità di rete. I kernel C-executive e PSX non contengono primitive per una gestione diretta di protocolli di rete. È fornito un insieme di librerie (CE-COMM), suddivise in due sottogruppi.
CE-TCP supporta i protocolli TCP, IP, ARP, ICMP, UDP, SLIP, PPP, oltre che X.25.
CE-SNMP (Simple Network Management Protocol) che supporta un protocollo standard per la gestione dello stato di rete.
Hardware di rete:
Ethernet Device drivers per SMC 8003/8013 (Elite 16, Combo 16), SMC 91C92, Intel 82596, AMD 7990 LANCE, e National Semiconductor DP83932B Sonic.
A SLIP/PPP driver per 8250 (e compatibili) DUART.