
Capitolo 1: Concetti fondamentali
1.1 TEMPO REALE E PARALLELISMO
1.2 MODELLI IMPLEMENTATIVI DI PARALLELISMO VIRTUALE
1.2.1 Time-driven.
1.2.2 Execution-driven multitasking.
1.2.3 Event-driven multitasking.
1.2.4 Considerazioni sulle tecniche presentate.
1.3 MODELLO A PROCESSI SEQUENZIALI COMUNICANTI
1.3.1 Stati dei processi
1.3.2 Come gli eventi producono transizioni di stato
1.4 SCHEDULING TEMPORALE - PREEMPTION
1.4.1 Non-preemptive scheduling
1.4.2 Preemptive scheduling
1.4.3 I piu' diffusi algoritmi di scheduling temporale
1.5 INTERRUZIONI - PRIORITA' - ANNIDAMENTO
1.5.1 Livelli di annidamento
1.6 COMPETIZIONE E COOPERAZIONE
1.6.1 Correttezza - Sincronizzazione - Mutua esclusione
1.7.1 Generali
1.7.2 Temporizzazione
1.7.3 Sincronizzazione
1.7.4 Comunicazione
1.7.5 Primitive di gestione di risorse
1.7.6 Gestione delle eccezioni
1.7.7 Descrittore dinamico di processo
Un sistema di elaborazione dovrebbe avere le seguenti caratteristiche:
Naturalmente il sistema operativo, implementando sulla macchina fisica una macchina virtuale, ha molta responsabilità nel raggiungimento di questi obiettivi.
Vi sono molte situazioni in cui il comportamento temporale di un sistema è fondamentale, ad esempio nell'interazione con il mondo esterno, sede di fenomeni asincroni.
Bisogna anche precisare che alcune attività legate al tempo vanno svolte anche in un normale calcolatore monoprogrammato e monoutente (vedi le interazioni con le unità periferiche).
1.1 TEMPO REALE E PARALLELISMO
In un ambiente di elaborazione in tempo reale l'esecuzione di un lavoro si può considerare corretta solo se sono rispettati certi vincoli temporali.
In un tale sistema il carico di lavoro è scomponibile in tre componenti:
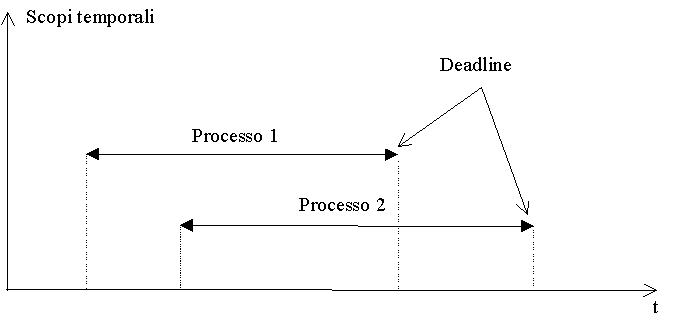
Lo scopo temporale di un'azione è l'intervallo di tempo tra l'istante in cui si verifica l'evento (esterno, temporale o interno) che attiva l'azione (triggering event) e l'istante in cui tale attività deve essere completata (deadline).
Si definisce deadline (scadenza finale) l'istante temporale che non deve essere superato dallo scopo temporale di un'azione.
Se alcune attività hanno azioni i cui scopi temporali presentano sovrapposizioni (overlapping), allora tali attività vengono dette concorrenti. Se invece non vi sono scopi temporali sovrapposti le attività vengono dette sequenziali.
Si noti che un'elaborazione ad attività concorrenti non è detto che sia necessariamente di tipo real-time.
Lo è soltanto se l'inizio e la fine di alcuni o di tutti gli scopi temporali delle azioni che la compongono sono vincolati da specifiche temporali.
Un processo sequenziale è un'attività internamente sequenziale caratterizzata da un proprio contesto, cioè dall'insieme delle risorse ad essa allocate, con i rispettivi stati. Tali risorse possono essere attive (processori) o passive (periferiche, memoria, dati, ecc.).
Un processo, per essere eseguito, richiede una risorsa attiva ed eventualmente delle risorse passive.
Il parallelismo tra diverse elaborazioni è la capacità di iniziare una nuova azione anche se altre sono già in corso.
Siano:
Condizione sufficiente perché sia richiesto un parallelismo di esecuzione è che esistano almeno due eventi tra loro aperiodici, che iniziano gli scopi temporali rispettivamente dell'azione i e j, per cui sia:
TDi < TEi + TEj
Condizione sufficiente perché si possa evitare la preemption, se TDj è la più breve deadline, è che sia:
∑ TEi < TDj.
Un parallelismo fisico è ottenibile se sono disponibili tanti processori (multiprocessing), quante sono le attività potenzialmente concomitanti. Ciò implica un'assegnazione (scheduling) spaziale delle attività alle risorse.
Ogni risorsa rimane inattiva (idle) per tutto il tempo in cui non è richiesto lo svolgimento di azioni dell'attività assegnatale.
Un'applicazione non è fisicamente realizzabile se si ha, per almeno un'azione:
TEi > TDi.
Il parallelismo virtuale si ottiene con l'assegnazione distribuita nel tempo delle risorse alle azioni in corso durante intervalli di tempo interni ai loro scopi temporali (multitasking).
Dovrà quindi esserci uno scheduling temporale.
Definiamo ora il coefficiente di utilizzazione del processore:
U = ∑i=1..n (TEi / TAi)
n = numero di azioni potenzialmente richieste al processore
TEi = tempo di esecuzione netto dell'azione i-esima
TAi = intervallo tra le attivazioni dell'azione i-esima
La realizzabilità fisica con un solo processore impone che sia U < 1, che è condizione necessaria, ma non sufficiente, perché possano essere rispettati tutti i vincoli temporali.
Infine, si parla di parallelismo misto se abbiamo più processori, ognuno dei quali esegue più attività in parallelismo virtuale.
Con un unico processore, se U < 1 ed ogni azione è contenuta nel proprio scopo temporale, si ottiene un effetto "equivalente" a quello ottenibile da diversi processori in parallelo.
Infatti, le specifiche temporali richieste riguardano solo l'azione conclusiva di emissione del risultato finale e non specificano il comportamento nelle fasi intermedie.
Occorre dire che il parallelismo virtuale è molto importante anche nei sistemi multiprocessore, ed è molto usato per le seguenti ragioni:
1.2 MODELLI IMPLEMENTATIVI DI PARALLELISMO VIRTUALE
Queste tecniche implementative sono realizzate dal nucleo (kernel) del Sistema Operativo preposto alla gestione dei processi.
Esse sono classificabili in tre modelli:
.
Le informazioni in ingresso possono essere ottenute da una osservazione periodica (campionamento) di stati continui o discreti.
Nell'approccio time-driven ogni attività è implementata come una successione di azioni che consistono nella valutazione, ripetuta ad ogni campionamento, di una stessa funzione dei valori catturati in ingresso (Ii), di uno stato interno (Si), e che produce un valore di uscita (Oi), e l'eventuale nuovo valore dello stato interno (Si+1).
Questa modellizzazione corrisponde ad una rete sequenziale sincrona, o, equivalentemente, ad una funzione di trasferimento a tempo discreto.
Supponiamo che si debbano eseguire le attività concorrenti A, B e C con lo stesso periodo di campionamento.
L'esecuzione delle azioni è organizzata in questo modo:
E' time-driven perché tutte le azioni sono eseguite solo in base ad eventi temporali.
Qui gli eventi esterni giocano solo un ruolo passivo, e possono essere rilevati deducendoli dalle differenze dei valori campionati in ingresso. E' dominante il concetto di stato.
Lo scheduling delle azioni è statico (off-line), e non c'è preemption.
I pregi di questo modello sono:
Infatti il caso peggiore si ha quando un ingresso cambia subito dopo essere stato campionato all'inizio del ciclo i. Alla fine di tale ciclo le uscite corrisponderanno ancora al vecchio valore dell'ingresso, mentre le uscite terranno conto del nuovo valore solo alla fine del ciclo i+1.
I difetti di questo modello sono invece:
1.2.2 Execution-driven multitasking
.
Su richiesta si commuta dal contesto di un'attività a quello di un'altra. Si lascia al programmatore applicativo la possibilità, e quindi la responsabilità, di invocare questa commutazione di contesto.
Anche qui gli eventi esterni sono passivi.
Non vi è alcuna garanzia di rispetto di eventuali vincoli temporali. Per questo motivo questa tecnica è solo raramente utilizzata in applicazioni con requisiti di tempo reale "lasco".
1.2.3 Event-driven multitasking
.
Il sistema è reattivo perché reagisce agli stimoli costituiti da eventi esterni, i quali attivano (trigger) le esecuzioni di certe azioni.
Le attività sono eseguite da procedure software ben aggregate internamente e tra loro ben disaccoppiate, ed assumono la veste di processi, ognuno dotato di un proprio contesto.
Qui gli eventi esterni giocano un ruolo attivo, di solito mediante meccanismi di generazione di richieste di interruzione, e ciò costituisce la caratteristica qualificante di questo approccio.
Occorre adottare una politica di scheduling sia delle azioni di servizio alle interruzioni che dei processi.
1.2.4 Considerazioni sulle tecniche presentate.
L'approccio event-driven è quello più generale.
Un'applicazione complessa potrà comprendere:
Ci concentreremo ora sull'ultimo approccio, quello event-driven.
1.3 MODELLO A PROCESSI SEQUENZIALI COMUNICANTI
I processi sono attività dotate di un proprio contesto che competono per l'uso della CPU e che possono tra loro condividere codice, dati ed eventualmente altre risorse.
Distinguiamo tra due tipi di processi, i task ed i threads.
I task sono processi dotati di un contesto proprio che comprende anche aree di memoria proprie. Ogni task è ottenuto da una separata operazione di collegamento (linking).
I threads sono processi dotati di un proprio stack, ma che possono condividere variabili globali, essendo stati collegati nell'ambito della stessa operazione di linking.
Un task può contenere al suo interno più threads.
Durante la loro evoluzione, i processi sono caratterizzati da uno stato interno e da uno stato esterno.
Il primo è gestito dal processo stesso eseguendo istruzioni del set base ed è descritto dal valore del Program Counter, dei registri e delle sue variabili private.
Il secondo ne descrive la situazione rispetto all'ambiente complessivo ed è gestito dal Sistema Operativo, in occasione della esecuzione di primitive o di interrupt.
1.3.1 STATI DEI PROCESSI
Inesistente. Il codice principale non è stato ancora caricato nella memoria operativa.
Dormiente. Presente in memoria ma non ancora dotato di un contesto completo, cioè non ancora preso in carico dal sistema operativo.
Pronto. Può essere eseguito, ed è in attesa della CPU.
In esecuzione. Dispone della CPU. Nei sistemi preemptive ha priorità non inferiore a quella di ogni processo pronto. Può essere in esecuzione nel modo utente o nel modo sistema. Nel primo caso sta eseguendo procedure applicative, nel secondo sta eseguendo procedure appartenenti al sistema operativo che costituiscono servizi che esso mette a disposizione dei processi.
Interrotto. E' latente perché interrotto da una richiesta di servizio di interrupt, la quale può produrre eventi o risorse che possono portare nello stato ready altri processi che ne erano in attesa.
In attesa di evento. E' destinato a reagire ad un evento che deve ancora verificarsi, o sta aspettando risorse non ancora disponibili. Un processo può essere in attesa disgiuntiva di diversi eventi, ad esempio evento OR scadenza temporale (time out).
Sospeso. Non compete più per l'uso di risorse o della CPU. Un processo può passare volontariamente in questo stato oppure esservi collocato di forza dal sistema operativo in seguito ad eccezioni irrecuperabili.
1.3.2 COME GLI EVENTI PRODUCONO TRANSIZIONI DI STATO
Le transizioni di stato possono essere causate da:
Questo è un tipico diagramma stati-transizioni:
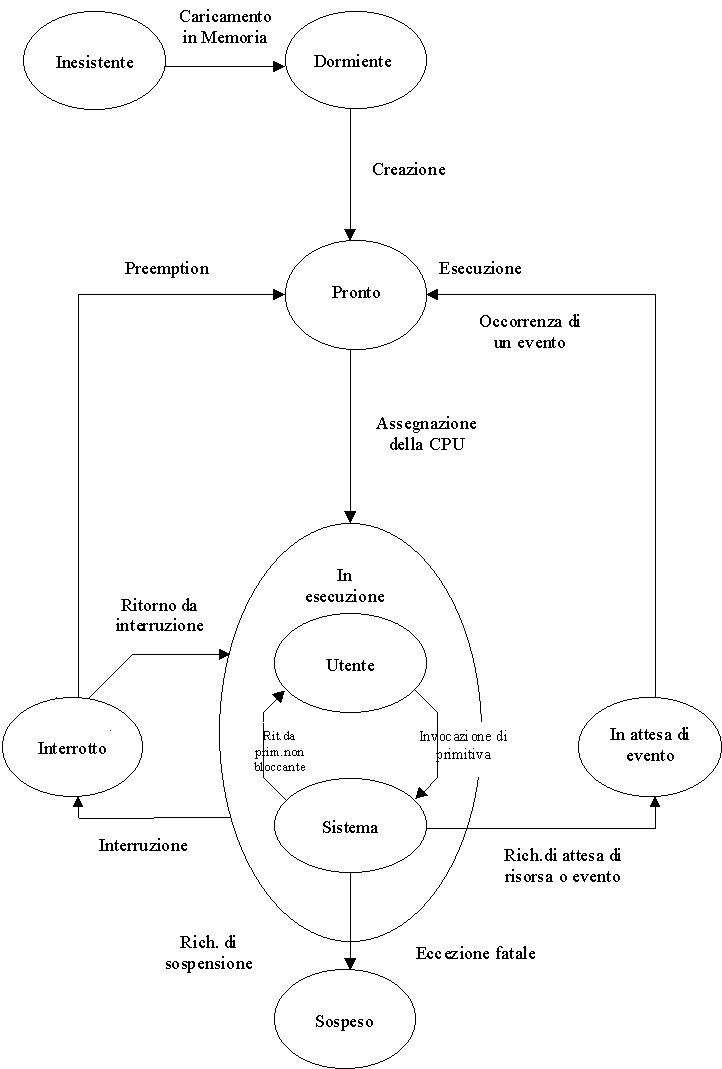
Caricamento in memoria. Fase non necessaria per quei sistemi dotati di memorie non volatili e che spesso sono privi di memorie di massa, come è il caso di molti controllori e sistemi embedded.
Creazione. Funzione seguita dal sistema operativo autonomamente in fase di inizializzazione, o su richiesta di un processo in esecuzione. Viene creato il contesto del processo, consistente in un'area di stack e un descrittore dinamico con opportuna inizializzazione.
Assegnazione della CPU. Preceduta da una fase di scelta del processo da attivare tra tutti quelli pronti (scheduling).
Invocazione di primitiva. Il processo in esecuzione invoca uno dei servizi messi a disposizione dal sistema operativo. In alcuni sistemi questa invocazione è implementata mediante istruzioni di software interrupt. I servizi possono completarsi subito oppure portare il processo in stato di attesa degli eventi che consentano la conclusione del servizio richiesto.
Ritorno da primitiva non bloccante. Avviene se il servizio è stato completato e non ha comportato il passaggio allo stato di pronto di un processo più prioritario di quello invocante.
Interruzione. Al termine dell'istruzione corrente (o del gruppo di istruzioni non interrompibili) quando nel frattempo sia stata segnalata una richiesta di interruzione e la CPU sia abilitata ad onorare tale richiesta. Questa transizione si verifica nello stato in esecuzione, sia in modo utente sia in modo sistema.
Ritorno da interruzione. A conclusione di un servizio ad interruzione che non abbia posto in stato di pronto processi più prioritari di quello interrotto, che quindi riprende la propria esecuzione "ignaro" dell'interruzione.
Preemption. Nell'ambito di un servizio di risposta a richiesta di interruzione, durante il quale venga portato nello stato di pronto un processo più prioritario di quello interrotto, che a sua volta viene posto nello stato di pronto.
Eccezione fatale. Le "eccezioni" (anomalie in esecuzione) vengono rilevate con diversi meccanismi che passano il controllo al sistema operativo. Se questo non è in grado di "recuperarle" deve forzare la sospensione del processo responsabile, di solito quello in esecuzione.
Richiesta di attesa di risorsa o evento. Quando il servizio invocato comporta la richiesta di attesa di una risorsa non disponibile o di un evento il processo richiedente viene posto in stato di attesa.
Occorrenza di un evento. Quando si verifica un evento atteso, la disponibilità di una risorsa richiesta o una scadenza temporale attesa o di time-out, il processo interessato viene posto nello stato di pronto.
Richiesta di sospensione. Un processo può inoltrare al sistema operativo la richiesta di terminare la propria esecuzione.
1.4 SCHEDULING TEMPORALE - PREEMPTION
L'operazione di scheduling consiste nella scelta di quale processo mandare in esecuzione.
Distinguiamo tra preemptive scheduling e non-preemptive scheduling.
1.4.1 NON-PREEMPTIVE SCHEDULING
Al termine del servizio di ogni interruzione il controllo viene ceduto al processo interrotto mentre era in esecuzione. Quindi ogni processo in esecuzione rimane tale fino a quando volontariamente invoca servizi del sistema operativo. Si ha così una notevole semplificazione nei rapporti fra i processi, visto che i cambiamenti di contesto vengono effettuati solo in occasione di chiamate al sistema operativo.
Inoltre viene minimizzato l'overhead associato ai cambiamenti di contesto, quindi con un miglior sfruttamento delle risorse e un miglior throughput.
Il grosso limite di questo approccio è che le prestazioni in tempo reale sono responsabilità del programmatore di processi e non sono garantite da sistema operativo.
E' la soluzione comunemente adottata. Ogni volta che assume il controllo, il sistema operativo ha l'occasione di individuare il processo più opportuno da attivare, in base alle scadenze temporali da rispettare per le varie elaborazioni.
La preemption si ha quando, al ritorno da un interrupt hardware, l'esecuzione non torna al processo interrotto, ma ad uno più prioritario diventato pronto in conseguenza del servizio dell'interrupt. Quindi la preemption può verificarsi in tutte le parti del processo in cui è abilitato l'interrupt.
Affinché le mutue interazioni fra i processi siano corrette:
1.4.3 I PIU' DIFFUSI ALGORITMI DI SCHEDULING TEMPORALE
Gli obiettivi dello scheduling sono diversi:
Round robin. I processi sono collocati in una sequenza fissa che viene ciclicamente scandita. Ad ogni operazione di scheduling si incrementa l'indice del vettore di processi e viene selezionato per l'attivazione il primo trovato pronto. Giunti in fondo al vettore si riprende dalla prima posizione. Ad un processo può essere assegnato un quanto di tempo (time slice), al termine del quale il processo, se è ancora in esecuzione, subisce una preemption. Ciò consente una migliore predicibilità dei casi peggiori dei tempi di esecuzione dei singoli processi. Infatti i tempi massimi di esecuzione possono essere calcolati pensando che ad ogni processo è concessa la frazione 1/N della potenza di calcolo.
Questo algoritmo ha come pregi:
I suoi difetti sono invece:
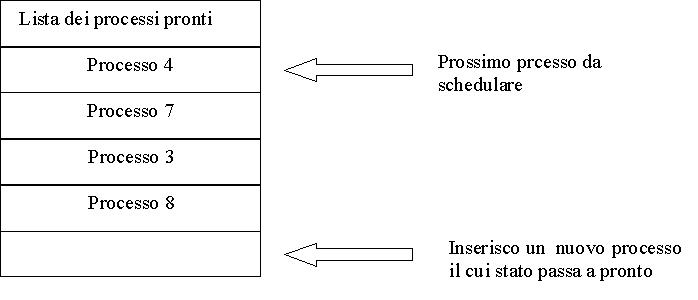
FIFO. Quando i processi diventano pronti sono collocati in fondo ad una coda FIFO. Viene estratto per l'attivazione il primo processo nella coda.
Pregi:
Difetti:
Fixed Priority. Ad ogni processo è assegnato staticamente un livello di priorità. I processi pronti sono in una coda ordinata per priorità decrescenti. Viene attivato il processo in testa alla coda. Se più processi hanno la stessa priorità, si utilizza per essi il criterio FIFO.
Pregi:
Difetti:
Rate monotonic. E' un metodo a priorità fissa usato quando i processi sono caratterizzati da:
Viene garantito il rispetto delle scadenze di tutti i processi se:
Questo algoritmo è ottimo.
Earliest deadline. Qui la priorità viene assegnata dinamicamente ai processi. Il processo più prioritario è quello che ha la deadline più vicina nel tempo, che ovviamente lo scheduler deve conoscere.
Anche questo algoritmo è ottimo.
Minimum laxity. Qui viene considerato più urgente il processo meno dilazionabile. La laxity (dilazionabilità) di un processo è la differenza tra la distanza dalla deadline ed il tempo netto di elaborazione ancora da eseguire.
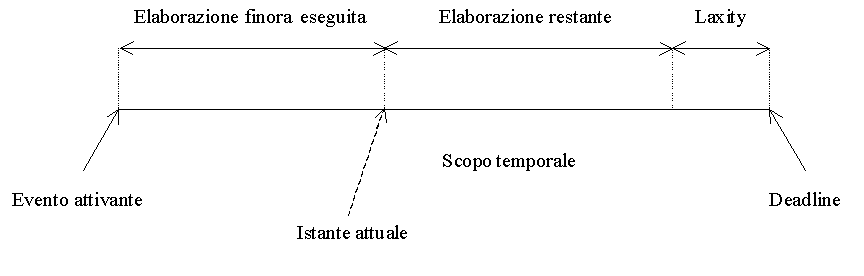
Perciò qui lo scheduler deve conoscere anche i tempi di esecuzione dei processi e tenere aggiornato il conto del tempo di esecuzione rimanente.
Anche questo algoritmo è ottimo.
Ricordiamo che un algoritmo è ottimo quando garantisce il rispetto di tutte le scadenze in tutte le situazioni in cui ciò è possibile (feasible).
Nella pagina seguente viene illustrato un esempio di scheduling a priorita in cui lo stato della coda cambia a seguito dell'entrata in attesa di un processo.
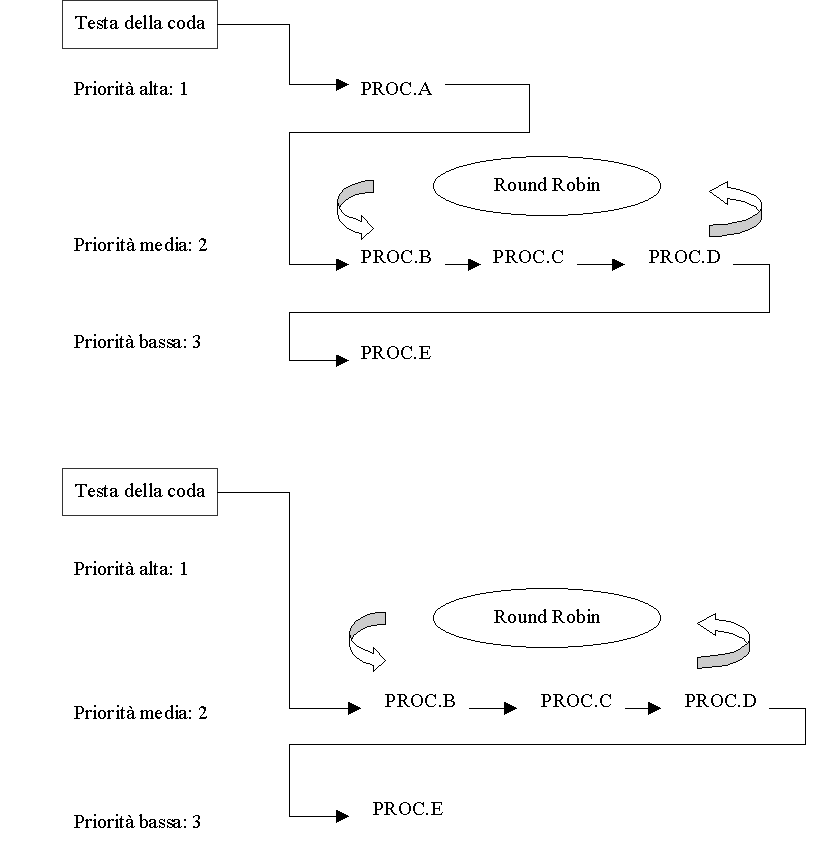
Figura 1.1. Esempio di scheduling basato sulle priorità: si vede prima la condizione iniziale della coda e poi lo stato della coda dopo che il processo A è entrato nello stato di attesa.
1.5 INTERRUZIONI - PRIORITA' - ANNIDAMENTO
Nella maggior parte delle applicazioni di automazione il servizio alle interruzioni è fortemente dipendente dai particolari dispositivi e quindi non può essere eseguito da procedure standard del sistema operativo. E' il programmatore applicativo che deve farsi carico della stesura delle relative routine di risposta (ISR).
Un approccio implementativo può essere il seguente:
Nelle applicazioni in tempo reale è necessario tener conto del diverso grado di urgenza associato ai diversi servizi, cercando di ridurre la latenza dei servizi più urgenti. Per far ciò bisogna consentire un annidamento dei servizi di risposta.
Una risposta ad una interruzione può a sua volta essere interrotta da interruzioni più prioritarie, e solo quando essa dichiara concluso il suo compito possono essere accettate interruzioni di pari o inferiore priorità.
1.6 COMPETIZIONE E COOPERAZIONE
Nelle applicazioni di automazione i processi presentano più o meno strette relazioni di cooperazione. In questo caso un unico job è scomposto in diversi processi (tipicamente di tipo thread) principalmente per consentire la concorrenza (parallelismo virtuale) necessaria per supportare interazioni in tempo reale con fenomeni asincroni. Ad esempio un processo gestisce un'interfaccia di acquisizione dati, un altro realizza funzioni di controllo, un altro interagisce con l'operatore ed infine uno mantiene le comunicazioni con sistemi remoti.
1.6.1 TEMPORIZZAZIONE - SINCRONIZZAZIONE - MUTUA ESCLUSIONE
La temporizzazione consiste nell'eseguire particolari azioni in particolari istanti di tempo assoluto o relativo rispetto ad altri istanti.
La sincronizzazione serve a garantire che vengano rispettati i vincoli di precedenza tra le azioni che producono e le azioni che utilizzano informazioni, in modo da realizzare un parziale ordinamento temporale tra azioni.
La mutua esclusione serve a garantire che siano svolte in modo corretto operazioni che richiedono l'uso di risorse che in ogni istante possono essere in uso ad un solo processo. Esempi di risorse che richiedono mutua esclusione possono essere la stampante, aree di dati in memoria, procedure e funzioni non rientranti.
Queste tre funzioni possono essere realizzate in due modi:
Sono i servizi che il sistema operativo mette a disposizione dei processi.
Una buona parte delle attività del sistema operativo vengono svolte all'interno di queste procedure. Le rimanenti funzionalità sono attivate dalle interruzioni del real-time clock e delle interfacce hardware.
Vediamo ora una rassegna delle primitive tipicamente previste per applicazioni di elaborazione in tempo reale.
Create (Processo). Processo è un descrittore statico, strutturato a record, che contiene i valori degli attributi iniziali del processo, cioè priorità, ampiezza dell'area di stack richiesta, entry point, eventuali risorse private permanenti. La primitiva assegna al processo un suo contesto e inizializza un descrittore dinamico, ponendo il processo nello stato di Pronto. Poi o ritorna al processo chiamante o chiama lo scheduler.
Suspend. Pone il processo invocante nello stato Sospeso e poi cede il controllo allo scheduler.
Abs_Wait (abs_time). Pone il processo chiamante in stato di attesa, e associa al suo descrittore dinamico il valore abs_time. Poi cede il controllo allo scheduler. Sotto risposta a interrupt di RTC il sistema operativo mette nello stato Pronto il processo invocante quando t = abs_time.
Rel_Wait (rel_time). Come prima. Qui però l'attesa è di un intervallo di tempo, di durata rel_time.
Cyc_Wait (period). Riattivazione ciclica e periodica ad ogni intervallo pari a period.
_ tout (..., tout_time). L'attesa con time-out è associata all'attesa di altri eventi. Il processo invocante chiede di essere comunque svegliato dopo il tempo tout_time, se non si verifica l'evento atteso.
E' importante disporre della variante con time-out per tutte le primitive bloccanti.
A volte è utile che il processo che riceve l'evento prima dello scadere del time-out possa conoscere il tempo rimanente, da adottare come scadenza per la successiva richiesta di altri eventi. In questo modo si può imporre un intervallo di tempo globalmente concesso all'acquisizione di una sequenza di eventi.
L'approccio tipico consiste di primitive di basso livello che si basano sull'uso di semafori.
Wait (semaphore [, tout]). Decrementa semaphore. Se poi semaphore è > 0 torna al processo invocante, altrimenti mette il processo nello stato di attesa, indicando nel suo descrittore dinamico il semaforo su cui è in attesa e il tempo di tout eventuale.
Sotto risposta a RTC decrementa tout e se questo scade mette il processo nello stato di pronto. Se qualcuno fa Signal sul semaforo mette Pronto il processo. Ovviamente il processo deve poter distinguere tra le due cause di risveglio.
Signal (semaphore). Incrementa semaphore e se poi è > 0 mette nello stato di pronto il primo processo in attesa su quel semaforo. Il processo che esegue la Signal non rimane bloccato in attesa di quello che eseguirà la Wait sullo stesso semaforo. Per questo motivo la Signal può essere invocata anche all'interno di una ISR.
Le primitive di comunicazione si possono considerare come un'estensione delle primitive di sincronizzazione, a cui è però associato anche il trasporto di informazioni.
PRODUTTORE - CONSUMATORE DI EVENTI
Send_Mess (message, queue). Accoda il messaggio message nella coda queue (detta spesso mailbox), senza attendere il consumatore. Se la coda è a lista non c'è pericolo di coda piena.
Receive_Mess (queue, message [, tout]). Il processo riceve il primo messaggio nella coda queue, eventualmente attendendo che ne arrivi uno. E' spesso necessario prevedere una gestione con time-out.
Put_Char (char, buffer [, tout]). Inserisce il carattere char nel buffer (circolare) se c'è posto, altrimenti attende che si liberi un posto, eventualmente con il tempo limite tout.
Get_Char (buffer, char [, tout]). Attende, eventualmente con time-out, che ci sia un carattere nel buffer (circolare).
SCRITTORE - LETTORI DI STATI
Se le informazioni sono di tipo stato, si deve instaurare il rapporto scrittore-lettori. Qui le informazioni sono basate su variabili globali. Ci deve essere una mutua esclusione tra le operazione dello scrittore e quelle dei lettori.
CLIENT - SERVER
1.7.5 PRIMITIVE DI GESTIONE DI RISORSE
Le primitive di gestione di risorse sono generalmente di livello superiore e basano le temporizzazioni, sincronizzazioni e comunicazioni necessarie al loro interno, sulle primitive di base già viste.
I sistemi operativi adatti al supporto del tempo reale di solito supportano in modo adeguato almeno la gestione delle risorse "convenzionali" quali memoria ad allocazione dinamica (heap), memorie di massa, tastiera, linee di comunicazione, stampanti, ecc.
Invece le risorse specifiche dell'applicazione vengono gestite dal programmatore applicativo usando le primitive precedentemente viste.
1.7.6 GESTIONE DELLE ECCEZIONI
Questa gestione è molto importante per i sistemi di elaborazione in tempo reale.
Infatti questi sistemi devono mantenere una validità anche in presenza di errori, tentandone il recupero o almeno il confinamento, e comunque continuando le attività possibili (persistenza).
Una tecnica spesso usata si basa su una collezione di gestori di eccezioni scritti dal programmatore applicativo, a cui il sistema operativo cede il controllo su invocazione di apposite primitive, in occasione di specifiche interruzioni sincrone (trap) o quando rilevi direttamente situazioni anomale.
Problemi:
Tipiche primitive per la gestione di eccezioni sono:
On_exception (exception, exc_handler). Un processo chiede al sistema operativo di creare l'aggancio tra exception e il relativo gestore exc_handler.
Raise (exception). Invocata dalla routine che rileva l'anomalia exception.
Uno dei pochi linguaggi che prevedono direttamente un certo numero di funzioni per la gestione delle eccezioni è Ada.
1.7.7 DESCRITTORE DINAMICO DI PROCESSO
Per descrivere lo stato e il contesto di un processo si può usare una struttura dati di tipo record, spesso chiamata TCB (Task Control Block), associata ad ogni processo all'atto della sua creazione e che contiene le diverse informazioni che ne caratterizzano l'evoluzione.
Le informazioni contenute in questa struttura dati sono tipicamente:
La descrizione delle risorse allocate serve per:
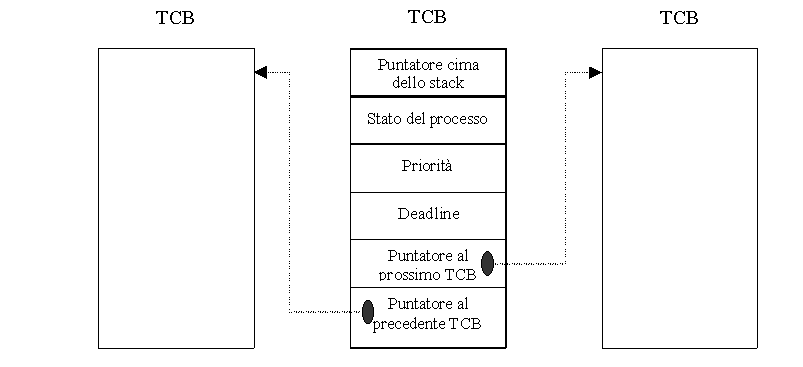
Figura 1.2. Esempio di una possibile implementazione della tabella TCB.