3 - CATEGORIE DI MIDDLEWARE
A questo punto, è interessante fornire una breve descrizione dei vari modelli di Middleware che si sono susseguiti ed evoluti fino ad oggi.
Come vedremo, essi si basano tutti sul modello client-server per l'integrazione di applicazioni distribuite.

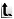
3.1 MIDDLEWARE BASATO SUI MESSAGGI (MESSAGE-BASED)
Message-based Middleware è stata una delle prime tecnologie che si è servita del concetto di bus di comunicazione comune tra le applicazioni che volevano poter interagire.
Come si può intuire, questa interazione viene soddisfatta tramite lo scambio di dati e controlli contenuti in strutture dati genericamente chiamate messaggi.
Tali messaggi sono delle stringhe di byte che contengono informazioni utili per le applicazioni, eventualmente integrati da informazioni di controllo per memorizzare, indirizzare e recuperare i dati durante le loro transizioni nel bus di comunicazione.
Grazie a questa tecnica, si evita al programmatore di applicazioni distribuite di occuparsi dei livelli più bassi dei protocolli di rete e delle chiamate fornite dai vari sistemi operativi.
Questa categoria di Middleware è la più confusa oggi. Non esiste un linguaggio standard per scambiarsi i messaggi; ogni prodotto ha il suo linguaggio proprietario. Non c'è un comune set di funzionalità garantito da ciascun prodotto.
Ad oggi, ci sono più di una dozzina di produttori di Middleware orientato ai messaggi, ciascuno con il proprio linguaggio di comunicazione e con le proprie funzionalità di base.
Risulta quindi difficile racchiudere questi tipi di prodotti in un'unica categoria che li comprenda tutti. Il risultato è che tali prodotti possono venire categorizzati in tre gruppi:
- Scambio di messaggi (message passing)
- Code di messaggi (message queuing)
- Pubblica e sottoscrivi (publish & subscribe)
Un tipico prodotto rappresentativo del primo gruppo è la piattaforma PIPES di PeerLogic; per il Middleware orientato alle code di messaggi abbiamo DECmessageQ di Digital Equipement, MQSeries di IBM e Falcon di Microsoft; infine, per la categoria publish/subscribe abbiamo TIB di Tibco.
I prodotti orientati allo scambio di messaggi offrono un modello di comunicazione diretta tra le applicazioni. In tal modo una richiesta di una applicazione ad un'altra applicazione deve avvenire in modo diretto; i programmi in causa stabiliscono un canale di comunicazione fisso per tutto il periodo dell'interazione.
Generalmente, tale modello implica un meccanismo di comunicazione sia sincrono (in cui il richiedente rimane in attesa finché giunge una risposta dal ricevente) che asincrono (in cui richiedente e ricevente sono logicamente sconnessi e tramite meccanismi di polling si può controllare se è giunta la risposta).
Comunque, il modello orientato allo scambio di messaggi è sempre di modo connesso, cioè un legame diretto tra i due programmi che vogliono partecipare allo scambio di messaggi deve essere mantenuto per tutta la durata degli scambi. Tale modello è generalmente incompatibile con la gran parte delle reti di telecomunicazione, soprattutto dopo l'introduzione dei protocolli a commutazione di pacchetto.
I prodotti orientati alle code di messaggi offrono invece un modello di comunicazione indiretta tra le applicazioni che partecipano allo scambio. Tale modello, infatti, offre una comunicazione di tipo non connessa tra i partecipanti: il canale di comunicazione non deve essere mantenuto fisso per tutta la durata dell'interazione. Questo è reso possibile grazie all'introduzione di un gestore di code al quale giungono, senza alcuna correlazione i messaggi che le varie applicazioni si scambiano. Esso le distribuisce, a seconda delle destinazioni, nelle code locali di ogni applicazione. In questo caso, quindi, l'applicazione controlla in polling la propria coda locale per sapere se è giunto qualche messaggio.
Tutto ciò permette ai programmi del sistema di operare in modo indipendente, senza dover instaurare connessioni logiche tra loro.
Le due precedenti categorie di Middleware permettono una comunicazione di tipo uno-uno ovvero ogni applicazione deve sapere a priori con chi comunicare. La categoria publish & subscribe assume un modello orientato agli eventi in cui ad ogni messaggio comunicato, solo chi è interessato risponderà. Quindi ogni applicazione, oltre alla possibilità di spedire messaggi in rete, avrà l'opzione di ignorare o rispondere ad altri messaggi a seconda che sia in grado o no di soddisfare le richieste. In questo modello si abbandona quindi il paradigma client-server: ogni applicativo può fungere da client o da server a seconda delle circostanze.
Ognuno dei modelli descritti è fortemente dipendente dal contesto in cui si vuole porlo, quindi non si può fare un confronto oggettivo prescindendo dal contesto applicativo. Possiamo però affermare che tale soluzione è da scegliere se si vuole avere un modello di comunicazione estremamente semplice e funzionale, basato su tecniche di programmazione tradizionali (da cui esula la programmazione ad oggetti).
I problemi principali di tale soluzione tecnologica riguardano la forte proprietarietà dei prodotti in commercio: non esistono standard di mercato. Questo vuol dire che non è possibile combinare prodotti di Middleware orientati ai messaggi di produttori diversi. Per cui, scelta tale soluzione, si resta legati alla tecnologia del produttore, caratteristica da evitare se si vuole avere un sistema sempre aperto e orientato alle nuove tecnologie.
Il secondo problema evidente è di tipo tecnologico: per come si svolge lo scambio di messaggi tra due applicazioni è sottinteso che entrambe debbano essere in grado di codificare e decodificare il messaggio, cioè possiedono il codice per permettere lo scambio di messaggi. Indipendentemente dalla categoria di Middleware, questa è una soluzione non molto elegante, perché ogni modifica al sistema di comunicazione si riflette sull'applicazione stessa e il programmatore deve quindi conoscere nei minimi dettagli il sistema di comunicazione per poter adattare il codice dell'applicazione alla modifica avvenuta. Si dice che il livello applicativo non è trasparente al sistema di comunicazione.
3.2 MIDDLEWARE BASATO SU REMOTE PROCEDURE CALL (RPC)
Come si intuisce dal nome, RPC richiama un concetto molto utilizzato nella programmazione tradizionale per applicarlo alla programmazione di entità distribuite.
Sappiamo benissimo che un programma di tipo tradizionale è composto da un corpo principale (body) e da una serie di procedure. Questa tecnica di programmazione era stata introdotta per avere una maggior strutturazione e leggibilità del programma, con conseguente riduzione e isolamento di eventuali errori.
Il modello client-server si adatta perfettamente a questo paradigma: molti programmi client hanno la possibilità di utilizzare delle procedure globali messe a disposizione dai vari server. Ogni procedura offre ai client un particolare servizio e, come nel caso della programmazione tradizionale, è inequivocamente determinata dalla sua interfaccia, ovvero dal suo nome e dai suoi parametri.
L'interfaccia dei server risulta quindi determinata dall'insieme delle interfacce delle procedure che essi contengono e mettono a disposizione dei vari client.
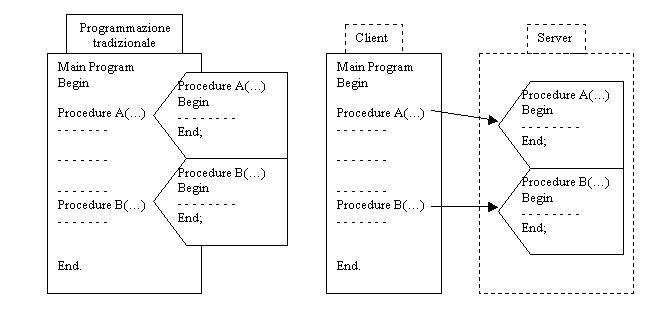
Questo modo di operare permette ai client di invocare procedure remote nello stesso modo con cui esso invoca procedure locali.
Inoltre, il programmatore di applicazioni client, non deve preoccuparsi della sincronizzazione tra le varie richieste remote, in quanto durante ogni richiesta, come il paradigma procedurale impone, il controllo viene passato in mano al server, il quale lo ritornerà al client richiedente solo dopo aver completato il servizio richiesto. Quindi il processo client rimarrà bloccato finché non giunge una qualche risposta da parte del server invocato (comunicazione sincrona).
Abbiamo detto che i client si comporteranno come se le procedure remote invocate fossero locali. In realtà, quando si invoca una richiesta su un server remoto, è necessario conoscere la sua logica di comunicazione, ovvero in che modo è predisposto per il passaggio dei parametri procedurali e di tutti i dettagli tecnici necessari ad una comunicazione remota (tipo di dati, formato, byte utilizzati, ecc.).
Risulta quindi indispensabile l'ausilio di un linguaggio standard di definizione delle interfacce in modo da rendere inequivocabile il contratto tra le applicazioni client e i server.
Le interfacce sono composte dal nome della procedura da invocare, i parametri passati tra client e server in entrambe le direzioni, e da un eventuale ritorno di risultati.
Lo standard di linguaggio che permette una descrizione delle interfacce del server indipendentemente dai linguaggi di programmazione utilizzati sui client e sui server è chiamato IDL (Interface Definition Language).
IDL consente quindi agli applicativi client di non preoccuparsi delle convenzioni dei linguaggi di programmazione usati per implementare i server. Inoltre, ogni client, può continuare ad utilizzare i propri costrutti di linguaggio. Infatti, una volta definito lo standard IDL, l'applicativo client viene analizzato da un compilatore IDL, il quale genera le IDL-routines (stub), ovvero le interfacce standard delle procedure invocabili dal client sul server.
Lo stesso meccanismo viene attuato sul server. IDL consente infatti di presentare in un formato standard e comprensibile ai client i servizi (le procedure) che offre.
La parte di codice che permette questo interfacciamento associata al client viene chiamata "client stub" mentre quella associata al server è chiamata "server stub".
Questo meccanismo consente ad applicativi eterogenei di collaborare tra loro attraverso la semplice invocazione di procedure, senza preoccuparsi se queste siano locali o remote e senza interessarsi dei meccanismi di comunicazione tra le varie macchine del sistema.
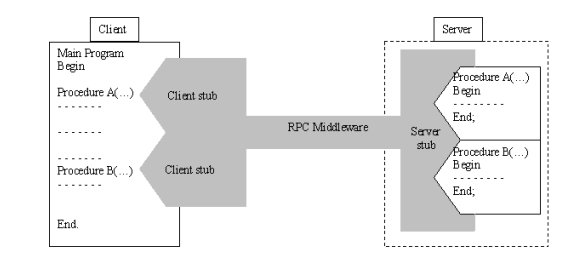
A differenza dei Middleware basati sullo scambio di messaggi, in questo caso IDL è uno standard globalmente accettato e riconosciuto. Sarà quindi possibile far collaborare tra loro differenti Middleware basati su RPC senza problemi di compatibilità.
Comunque, RPC Middleware ha avuto meno successo rispetto a quello basato sullo scambio di messaggi. Il motivo è di tipo metodologico-progettuale: in fase di progetto, la distribuzione di un sistema informativo viene analizzata molto presto, mentre la scrittura delle effettive procedure che andranno poi allocate sui vari server avverrà solo in fase di scrittura del codice, e quindi molto dopo aver stabilito la distribuzione dei servizi. L'utilizzo di meccanismi di RPC implica quindi la modifica dei correnti metodi di analisi e progetto di sistemi informativi, introducendo il concetto di servizi offerti dai server al più alto livello possibile.
Oltre alle motivazioni progettuali ci sono altri problemi di carattere più tecnologico che frenano l'utilizzo di Middleware basati su RPC.
Innanzitutto la non affidabilità delle comunicazioni. Se per un qualsiasi motivo un server o la rete cadesse mentre un client si trova in attesa della risposta ad una RPC, il sistema rimarrebbe bloccato fino al ripristino dei problemi e la comunicazione andrebbe comunque persa. Qualche venditore ha introdotto il concetto di transizione associato a quello di RPC.
Altro punto fondamentale da sottolineare è il tipo di comunicazione che avviene in tali sistemi: un client può comunicare con un server alla volta attendendo ogni volta che questo gli ritorni al più presto il risultato del servizio richiesto. In pratica non c'è la possibilità di instaurare comunicazioni di tipo uno-molti, ma solo di tipo uno-uno.
Inoltre, RPC generalmente impongono una relazione statica tra le diverse componenti di un sistema distribuito. Per la maggior parte delle applicazioni questo significa che una volta che l'applicativo client è stato compilato ed è stata creata la sua interfaccia stub client, i suoi legami con le procedure di un particolare server sono fortemente fissati e non alterabili in fase di esecuzione.
Tutto ciò è apertamente in contrasto con le esigenze di dinamicità richieste da qualsiasi sistema distribuito e ben offerte dai sistemi basati sullo scambio di messaggi.
Tipici prodotti rappresentativi di tale categoria di Middleware sono DCE (Distributed Computing Environment) di OSF e ONC della Sun. A riscontrare il maggior successo è sicuramente DCE, il quale è stato riproposto da numerosi venditori, uno per ciascun sistema operativo in commercio (Digital, IBM, HP, Sun, ecc.).
3.3 MIDDLEWARE ORIENTATO AGLI OGGETTI (OBJECT-ORIENTED): CORBA & DCOM
E' ormai da qualche anno che si è ampiamente riconosciuta una nuova metodologia di programmazione che rimane concettualmente molto più vicina alla parte di design di un progetto, rispetto alla programmazione procedurale che veniva considerata quasi esclusivamente nella parte implementativa. Tale nuovo modo di procedere è la programmazione orientata agli oggetti (OO), e prevede la definizione di entità chiamate appunto oggetti già in fase di modellizzazione del progetto. Tali oggetti sono costituiti da una parte visibile dall'esterno, detta interfaccia, la quale rappresenta le funzionalità dell'oggetto, e da una parte interna, chiamata implementazione dell'oggetto, la quale specifica come svolgere le funzionalità messe a disposizione dall'oggetto.
Il grande vantaggio di procedere in questo modo è che fin dalla fase progettuale si potranno definire le interfacce degli oggetti del nostro sistema che solo in un secondo momento, nella fase di scrittura del codice, andranno implementate. In questo modo si riesce a portare ad un livello molto elevato nella catena di produzione del software, un aspetto che fino a pochi anni fa era puramente implementativo e che quindi veniva preso in considerazione soltanto nell'ultima fase di scrittura del codice.
La programmazione orientata agli oggetti permette quindi al progettista di avere una visione generale di quelli che saranno dei dettagli implementativi, già nella fase di costruzione del progetto.
Brevemente, anche perché in questo ambito daremo per scontate le nozioni di programmazione ad oggetti, ogni oggetto di una classe ha un nome, degli attributi per definirne lo stato e dei metodi per descrivere il proprio comportamento.
Come abbiamo già accennato, per ogni oggetto sono separati gli aspetti esterno, con la sua interfaccia, e interno con i propri metodi e attributi.
Questo permette di identificare un insieme (o sistema) di oggetti tramite la lista delle interfacce associate agli oggetti del sistema. Quindi è possibile modificare il codice di un oggetto senza modificare la sua interfaccia e quindi senza modificare le interazioni che aveva l'oggetto con il mondo esterno.
Ultima caratteristica, ma non meno importante, è l'ereditarietà, ovvero la possibilità di definire nuovi oggetti ereditandoli da altri già esistenti. Questo meccanismo risulta fondamentale quando si parla di riuso di software.
Terminata la breve introduzione al mondo degli oggetti torniamo al problema che ci riguarda: un Middleware orientato agli oggetti.
Se immaginiamo un sistema in cui vari oggetti sono distribuiti in una rete di comunicazione, allora creare un canale di comunicazione tra applicazioni vuol dire permettere ai vari oggetti di rendere pubbliche le proprie interfacce di modo che gli altri oggetti possano invocare i suoi metodi. Avremo quindi, in questo caso, un oggetto cliente che invocherà dei metodi di un oggetto server. Tale richiesta è resa possibile utilizzando un Middleware ad oggetti, detto anche OBJECT REQUEST BROKER (ORB).
Questo modello di comunicazione è concettualmente simile alla richiesta di procedure remote (RPC): l'oggetto client non conosce la locazione dell'oggetto server a cui richiede l'esecuzione di un metodo e non deve neanche conoscere il modello di invocazione utilizzato da quel particolare server, ovvero formato dell'invocazione e dell'eventuale risposta.
Come il paradigma ad oggetti impone, la comunicazione tra client e server può avvenire sia in modo statico che dinamico:
- La comunicazione statica è ottenuta nello stesso modo in cui avveniva la richiesta di procedure nel modello RPC. Tramite un linguaggio standard IDL orientato alla comunicazione tra oggetti si definiscono le interfacce degli oggetti che si affacceranno sul sistema distribuito. In questo modo vengono a formarsi gli "stub" client e server, che permettono la comunicazione tra oggetti client e server, rispettivamente, attraverso il Middleware orientato agli oggetti.
- La comunicazione dinamica avviene invece in fase di esecuzione. Ogni oggetto client può infatti interrogare il Middleware orientato agli oggetti in modo da conoscere le effettive interfacce degli oggetti disponibili sulla rete. Il server che riceve una richiesta di invocazione non sarà in grado di stabilire se essa è avvenuta in modo dinamico o statico.
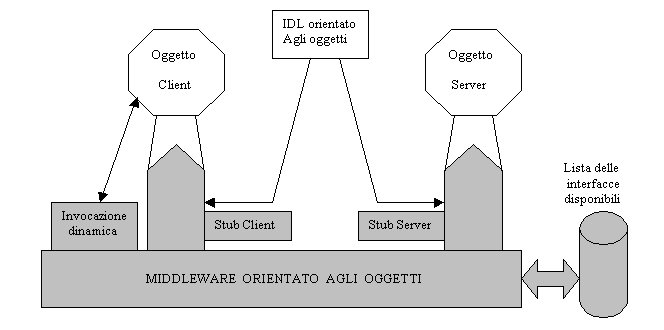
Il paradigma orientato agli oggetti, insieme al Middleware per oggetti, propongono una nuova visione di sistema informativo: l'insieme delle interfacce degli oggetti di un sistema rappresentano i servizi offerti da tal sistema. Quindi un sistema non viene più descritto come un insieme di applicazioni, ma come un insieme di servizi. Il grande interesse rivolto ai Middleware orientati agli oggetti è dovuto al fatto che contengono un database costantemente aggiornato riguardo i servizi che il sistema mette a disposizione. E' quindi possibile, in ogni momento, consultare tale lista in modo da conoscere, dinamicamente, le possibilità offerte dal sistema.
Oggigiorno due modelli di Middleware orientati agli oggetti coesistono.
Il primo modello è stato proposto nel 1990 dall'organizzazione internazionale degli standard OMG. Il suo nome è CORBA (Common Object Request Broker Architecture).
Esso è stato definito solo concettualmente; diverse case hanno poi creato la propria versione implementata di CORBA: ObjectBroker da Digital Equipement Corporation, DSOM da IBM, DOE da Sun ORBPlus da HP e Orbix da IONA, per citarne alcuni.
Il secondo modello è stato proposto invece da Microsoft con COM (Component Object Model), successivamente esteso (nel 1996) a DCOM (Distributed COM).
Quindi il modello di Microsoft è stato ideato per proporsi come alternativa a CORBA.
In realtà, grazie alla grossa fetta di mercato che quest'ultimo dispone e al fatto che tutto il software Microsoft è basato sul modello COM, è stato piuttosto CORBA a doversi adattare in modo da poter comunicare con DCOM.
Daremo di seguito una breve esposizione generale su i due principali Middleware orientati agli oggetti.
3.3.1 Common Object Request Broker (CORBA)
CORBA è un insieme di specifiche definite da Object Management Group (OMG), un consorzio il cui scopo è quello di definire un'insieme di interfacce per software interoperabile orientato agli oggetti. Tali specifiche stabiliscono il modo in cui questi oggetti andranno definiti, creati, invocati, trasportati e come potranno comunicare tra loro.
Quindi CORBA fornisce il meccanismo con cui un oggetto client andrà a chiedere un servizio ad un oggetto server, indipendentemente dall'architettura delle macchine dalle quali i due oggetti derivano.
Abbiamo già visto come questa architettura sia simile al meccanismo delle RPC, e, come RPC, utilizza lo standard IDL, il linguaggio di specifica delle interfacce tra client e server.
Comunque IDL per CORBA ha subito delle modifiche per poterlo adattare al paradigma orientato agli oggetti.
Caratteristica fondamentale di CORBA rimane però lo standard di interoperabilità che permette ad oggetti su macchine diverse, o addirittura appartenenti al dominio di differenti implementazioni di CORBA, di comunicare.
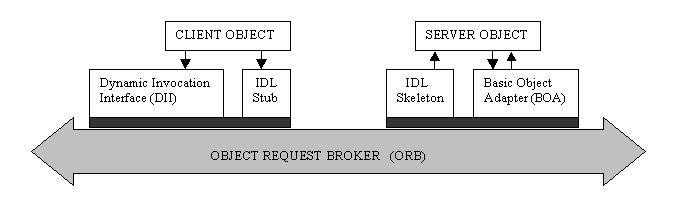
Come mostrato in figura, i principali componenti di CORBA sono:
- Il cuore di CORBA, ovvero l'ORB, il componente software attraverso cui gli oggetti del sistema fanno le richieste e ricevono le risposte. Ogni tipo di comunicazione nel sistema distribuito avviene tramite ORB. La sua implementazione non è specificata dallo standard CORBA, e quindi esistono tante versioni dell'ORB quanti sono i prodotti sul mercato.
- Il BOA (Basic Object Adapter) rappresenta l'interfaccia tra l'ORB e le applicazioni server a disposizione. Esso indirizza le richieste provenienti dall'ORB ai server in grado di rispondere. Si preoccupa quindi di conoscere i servizi offerti dai server del sistema, in modo da poter indirizzare le richieste provenienti dai client.
- Static Invocation Interface (SII) è l'interfaccia IDL utilizzata dai client per poter invocare servizi. E' disponibile in fase di pre-compilazione, ovvero il contratto tra client e server è conosciuto e fissato a priori.
- Dinamic Invocation Interface (DII) è l'interfaccia disponibile run-time per quei servizi che vengono offerti solo in fase di esecuzione del sistema. Generalmente esiste un repository di sistema che contiene tutti i servizi disponibili in ogni istante. Quei servizi che non sono compresi nello stub della SII potranno essere invocati solo tramite richiesta dinamica.
Dal punto di vista della comunicazione, CORBA permette sia operazioni sincrone che asincrone. SII supporta solo richieste sincrone, quindi il client rimarrà bloccato finché il server ritornerà una risposta. Tramite DII è possibile avere comunicazioni asincrone, solo che il client dovrà periodicamente controllare sull'ORB se la risposta è ritornata.
In aggiunta alle funzionalità di base del Middleware, CORBA mette a disposizione dei servizi. Alcuni di essi sono essenziali per lo sviluppo di applicazioni mission-critical. Altri rappresentano funzionalità specializzate utili solo per alcuni tipi di applicazioni.
Mentre le funzionalità di base sono riportate da tutte le implementazioni in commercio dell'ORB di CORBA, non è altrettanto vero per i CORBAservice. Ad oggi, tali servizi variano enormemente tra i diversi produttori di CORBA, anzi, si potrebbe benissimo affermare che il supporto di tali servizi è una chiave di paragone e differenziazione tra i vari produttori.
Ne diamo di seguito un conciso elenco dei principali:
- Naming - è un servizio di directory e consente di riferirci agli oggetti tramite nome e non tramite indirizzo fisico della loro locazione.
- Eventi - fornisce un canale di comunicazione per eventi, pensato per poter lavorare in modo asincrono.
- Transazioni - fornisce le funzionalità transazionali (ad es. proprietà acide) per le comunicazioni tra oggetti.
- Controllo di concorrenza - coordina l'accesso di applicazioni client su risorse condivise.
- Ciclo di vita - definisce le convenzioni per creare, cancellare, copiare e muovere oggetti.
- Persistenza - fornisce un set di interfacce comuni per memorizzare lo stato degli oggetti per mantenere la persistenza del sistema.
- Sicurezza - definisce le interfacce di sicurezza essenziali per proteggere un'applicazione distribuita orientata agli oggetti.
3.3.2 Microsoft OLE/COM/DCOM
Il secondo modello di Middleware basato sugli oggetti è stato proposto da Microsoft con la tecnologia OLE/COM, estesa in seguito ad OLE/DCOM (Distributed).
Data la rilevanza di Microsoft sul mercato mondiale, tale modello è divenuto immediatamente un'alternativa al modello proposto da OMG.
Tutto il software di Microsoft è basato sulla tecnologia Component Object Model (COM) e quindi chiunque voglia cooperare con prodotti Microsoft deve poter interagire con il modello ad oggetti COM. La rilevanza mondiale dei prodotti Microsoft consente di elevare al rango di "standard de facto" qualsiasi prodotto o tecnologia emessa.
E' questo il motivo che ha spinto l'OMG a cercare il modo di far comunicare il mondo CORBA con quello COM (tuttora ci stanno lavorando).
OLE è una collezione di tecnologie di alto livello costruite sul paradigma e sull'infrastruttura di DCOM.
Dal punto di vista del Middleware, DCOM è molto simile a CORBA. Esso permette agli oggetti di essere definiti, creati, inviati, invocati, e fatti comunicare tra loro. Anche per DCOM esiste un linguaggio IDL di tipo proprietario che consente di definire in modo univoco le interfacce degli oggetti disponibili nel sistema.
Andiamo ad analizzare più in dettaglio la tecnologia COM di Microsoft:
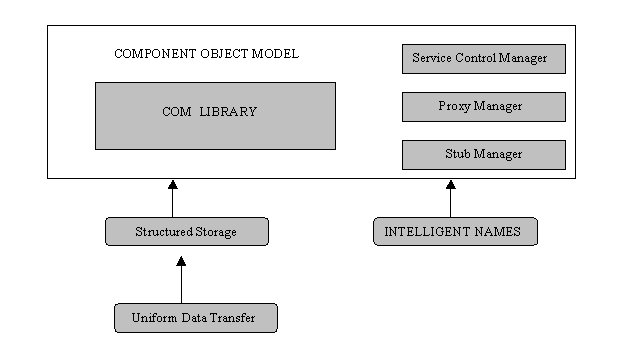
Il cuore dell'architettura è il Component Object Model, il quale gestisce la creazione e la distruzione degli oggetti, la loro definizione, il loro instradamento e l'interrogazione delle loro interfacce.
Il Service Control Manager (SCM) si occupa di scovare gli oggetti server e di creare canali di comunicazione tra client e server. Ogni volta che un client invoca una richiesta per un particolare oggetto, il SCM controlla se il server contenente l'oggetto invocato è attivo, altrimenti cercherà nel suo registro se c'è qualche server in grado di soddisfare la richiesta. Il SCM residente sul client stabilirà un canale RPC con il SCM residente sul server, in tal modo il client potrà invocare il servizio richiesto come se fosse una procedura locale. Per ottenere questo, però, i due SCM (client e server) dovranno caricare specifici stub (simili a quelli di CORBA), detti proxi stub, su entrambi i processi, client e server. In questo modo, i dati scambiati tra i due processi potranno venire perfettamente indirizzati nel canale RPC creato.
In pratica, il modello DCOM crea staticamente o dinamicamente delle interfacce in linguaggio IDL standard (Microsoft) in modo da permettere la cooperazione tra oggetti client e server tramite il paradigma delle Remote Procedure Call (RPC).
Come annunciato, Microsoft propone una sua personalizzazione dello standard IDL, linguaggio di specifica delle interfacce ad alto livello. Tale versione supporta il modello DCOM di specifica delle interfacce, ovvero una famiglia di operazioni o metodi logicamente correlati tra loro.
Sull'architettura COM (o DCOM) è fondato il paradigma OLE, il quale permette ad un qualsiasi oggetto client di formulare dinamicamente delle richieste e inviarle ad un oggetto server remoto. Tali richieste comprendono semplicemente il nome del metodo da invocare, i tipi e i valori dei parametri associati e le informazioni di routine correlate, essenzialmente come avveniva nel caso delle RPC.
Come con CORBA, un client interessato a dei servizi, può richiedere informazioni riguardo le interfacce server (servizi disponibili) in un Repository messo a disposizione dal sistema.
Anche il modello OLE/DCOM permette a tutti gli oggetti OLE/DCOM compatibili di poter venire interrogati dinamicamente (runtime) per avere informazioni circa le interfacce che supportano.
Questo è un punto fondamentale della tecnologia OLE/DCOM di Microsoft, infatti, diversamente da ciò che accadeva con CORBA, non è più necessaria una fase di creazione iniziale degli stub statici disponibili prima dell'avvio del sistema, tutto avviene dinamicamente. Con la tecnologia OLE/DCOM è consentito individuare in esecuzione i servizi disponibili e quindi operare di conseguenza.
In realtà Microsoft enfatizza molto questo punto, anche se CORBA, tramite le invocazioni dinamiche, raggiunge lo stesso obiettivo.
Per dare un esempio pratico, pensiamo ad un sistema bancario composto da un unico server centrale e numerosi client disposti sui vari nodi di una rete, i quali devono accedere ai servizi del server, come ad esempio controllare un account. Cosa accadrebbe se una nuova versione del metodo che consente il controllo degli account diviene disponibile sul server? Se disponessi solo di una invocazione statica dei servizi, allora dovrei andare ad informare tutti i client dell'avvenuto cambiamento, altrimenti questi continuerebbero ad utilizzare il vecchio metodo. Se invece avessi a disposizione un controllo dinamico delle interfacce dei metodi disponibili sul server, potrei accorgermi automaticamente del nuovo servizio disponibile e quindi andarlo ad invocare.
Il principale svantaggio del modello OLE/DCOM, comparato a CORBA, è nella sua natura proprietaria. In questo momento, OLE/DCOM non è ancora disponibile all'esterno dei sistemi operativi di Microsoft, sebbene alcuni patner Microsoft stiano lavorando su porte OLE/DCOM per altri sistemi operativi, incluse le piattaforme UNIX.
Una mancanza importante di OLE/DCOM è l'assenza completa dei servizi di Middleware che rendono la tecnologia facilmente adattabile per le esigenze degli utenti. Comunque, anche se i servizi come message queuing, distributed naming, sicurezza e transazioni non sono esplicitamente forniti da OLE/DCOM, sono disponibili in modo implicito e nascosto dai sistemi operativi di Microsoft. Ma questo fa si che la tecnologia sia maggiormente legata alle piattaforme utilizzate. Possiamo quindi affermare che Microsoft non supporta l'eterogeneità.
CORBA e OLE/COM sono due tipi di Middleware orientati agli oggetti che condividono alcune caratteristiche ma che si differenziano per molte altre.
Questo è il motivo sostanziale che spinge l'utenza ad un utilizzo cooperativo di tali tecnologie. E' necessaria però una interoperabilità bidirezionale tra CORBA ed OLE/COM. Tale interoperabilità dovrà permettere ad oggetti corba di parlare con oggetti COM e viceversa. Alcuni produttori, come Iona e Digital, offrono già soluzione a tale interoperabilità. Un altro approccio potrebbe però essere quello proposto da Visual Edge, sviluppando un adattatore di sistemi ad oggetti (Object System Adapter) che abbia come specifiche un ponte tra le due tecnologie.
Analizziamo di seguito, più in dettaglio, alcune differenza tra i due modelli di Middleware orientati agli oggetti:
- Innanzitutto occorre precisare che Microsoft DCOM è un prodotto, diversamente dal set di specifiche di CORBA.
- DCOM supporta le specifiche del modello binario (binary model) proposto da Microsoft. Tale modello è basato sulla standardizzazione della memorizzazione delle funzioni puntatori utilizzate per invocare i metodi degli oggetti. Questo consente l'indipendenza dal particolare linguaggio di programmazione che è stato utilizzato per implementare un oggetto. Ad esempio un programma client scritto in Visual Basic può accedere a dei metodi di un oggetto scritto in C++, ammesso che entrambi utilizzino il modello binario di memorizzazione dei dati. Dall'altro lato, la compatibilità binaria di CORBA è fortemente dipendente dal prodotto (produttore). Ultimamente, con l'emissione da OMG della versione CORBA 2, la quale prevede l'utilizzo di un protocollo di comunicazione standard (Internet Inter Orb Protocol, IIOP), sarà possibile interfacciare i vari prodotti tra loro (in particolare i vari ORB di case diverse).
- DCOM non supporta completamente l'ereditarietà multipla tra oggetti, una caratteristica che non dovrebbe mancare ad un modello che si dichiara orientato agli oggetti. Un oggetto DCOM può solo ereditare l'interfaccia di un altro oggetto, ma rimangono a lui ignoti i comportamenti interni e le strutture dati private dell'oggetto ereditato. In altre parole, una volta ereditato un oggetto conosceremo solo il suo comportamento esterno rappresentato dalle sue interfacce. Microsoft ha cercato un rimedio introducendo la definizione di interfacce multiple per ogni classe, in modo da poter facilitare l'introduzione di nuovi upgrade all'interno di progetti anche complessi. Comunque rimane molto pesante la mancanza di un completo supporto dell'ereditarietà multipla tra oggetti.
- DCOM supporta il binding ritardato, il quale permette agli sviluppatori di applicazioni client di non accordarsi in fase iniziale con compilatori IDL per creare stub statici che contengano tutte le interfacce utilizzate. Questo grazie al fatto che qualsiasi richiesta verso oggetti server viene costruita dinamicamente, venendo a conoscenza solo a runtime degli oggetti che un client può invocare. I prodotti CORBA, invece consentono un binding anticipato, tramite Static Interface Invocation (SII), e un binding ritardato, tramite Dynamic Interface Invocation (DII). Solo nel secondo caso il linguaggio di specifica delle interfacce IDL non è richiesto, in quanto esse verranno scoperte solo a runtime.
3.4 Windows DNA e JINI - PREMESSE
Nei prossimi capitoli analizzeremo più in dettaglio i sistemi di Middleware proposti da Microsoft e da Sun: DNA e JINI.
Il primo è un sistema che fornisce una tecnologia di base per poter realizzare sistemi distribuiti su rete. Vedremo infatti che DNA si fonda sui principi di DCOM, espansi nella nuova versione COM+.
Esso fornisce inoltre una serie di strumenti per il supporto alla realizzazione di sistemi distribuiti su una rete di calcolatori composta da macchine in tecnologia Microsoft.
Come vedremo, esso è composto da un insieme di tool il cui scopo è aiutare e condurre il progettista verso la realizzazione di sistemi distribuiti performanti dal punto di vista della scalabilità, della sicurezza, della autonomia e di tutte le caratteristiche importanti, quando si parla si sistemi su rete di calcolatori.
Vedremo più avanti se Microsoft ha veramente raggiunto tali obiettivi.
JINI, nasce con degli obiettivi simili, ma con profonde diversità dal punto di vista di intendere un sistema di Middleware, rispetto alla idea di Microsoft.
Middleware, per la Sun (realizzatrice di JINI), è una infrastruttura in grado di consentire l'interoperabilità tra sistemi che operano su rete, indipendentemente dalla tecnologia (e quindi dal Sistema Operativo) con cui sono realizzati. Tale forza, viene alla Sun dallo sviluppo naturale che ha avuto il linguaggio Java per la programmazione su Web. Praticamente, oggi, non esiste sistema operativo in commercio che non consenta la lettura e l'esecuzione di un applet Java scaricato via Web. Questo ha portato la sun a lavorare ed espandere la versione iniziale della Java Virtual Machine per poterla utilizzare come strumento di cooperazione tra diversi sistemi posti in rete.
Quindi, mentre Microsoft, con DNA, impone una tecnologia di base per poterne usufruire i benefici, JINI della Sun sfrutta l'estensione della JVM su tutti i sistemi operativi commerciali per realizzare una infrastruttura che consenta la cooperazione di oggetti Java su rete di comunicazione.
Questo è sostanzialmente lo spirito con cui le due grandi software house si pongono sul mercato in termini di sistemi di Middleware.
Vedremo, nel corso del trattato pregi e difetti dei due sistemi, e fino a che punto hanno raggiunto gli scopi che si erano preposti.