|
|
|
|
Fault tolerance nei sistemi Tandem Quello che vogliamo analizzare, è come viene implementato il FT in un sistema con hardware dedicato. Vedremo inoltre l’utilizzo di alcune nuove idee per il FT, dedicate a settori specifici.
1. Introduzione Il sistema che noi vogliamo analizzare è di tipo singolo – errore – FT [2]. A livello hardware, il sistema è multiprocessore, con moduli di connessione a doppio percorso (dual paths), è possibile la diagnostica e la manutenzione online. É possibile interconnettere più CPU tramite una rete locale gerarchica FT. Tutte le periferiche che sono necessarie per le transazioni sono comandate da controllers a doppia porta. Il sistema software prevede i processi e i messaggi come meccanismi strutturati di base. I processi servono per la modularità del software e per l’isolamento dei guasti. Le applicazioni sono costruite in modo da richiedere i processi tramite RPC verso un processo server. Le classi di processi server utilizzano i multiprocessori. Il processo complessivo astratto risultante è un sistema distribuito che può utilizzare migliaia di processori. Per le transazioni distribuite e per i dati distribuiti si è utilizzato un database relazionale. In generale il sistema in questione ha un MTBF di anni (in confronto ad altri sistemi di guasto – singolo – tollerato che hanno MTBF di circa 2 settimane) tenendo conto di tutti i possibili fattori di guasto. L’unico guasto non tollerato è il disastro che distrugge totalmente il sistema, perché si può arrivare al massimo ad una macchina distribuita con bus che arrivano a 4 Km.
2. Principi generali di design I principi di base sono i seguenti: Modularità: sia l’hardware che il software sono decomposti in moduli di granularità fine che rappresentano le unità di servizio, guasto, diagnosi, riparazione. Blocco immediato: ogni singolo modulo prevede una diagnosi interna: se un guasto viene scoperto, esso si ferma immediatamente. Guasto singolo: il sistema è in grado di reggere un singolo guasto e il suo tempo di riparazione senza risentirne. Manutenzione online: l’hardware e il software possono essere riparati mentre tutto continua a funzionare e una volta che sono riparati, la loro reintegrazione non crea interruzioni. Interfaccia utente semplificata: si è cercato di automatizzare e semplificare l’interfaccia dell’utente verso il sistema, perché un interfaccia molto complessa, può essere causa di guasto. 3. Hardware 3.1 Principi Guardando da un punto di vista esterno, si vede che mettere due moduli per ogni tipo è in genere sufficiente perché la probabilità di un secondo guasto sul modulo duale durante il tempo di riparazione del primo é estremamente bassa. Ad esempio se un processore ha un MTBF di 1 anno, un sistema a doppio processore ha un MTBF di 1000 anni. Aggiungendo invece ulteriori processori, non porta ad avere un sostanziale guadagno di affidabilità. La modularità è senz’altro necessaria, perché porta ad una facile sostituzione dei singoli pezzi. L’indipendenza tra i singoli moduli è necessaria affinché il guasto di un singolo non si propaghi. Anche il blocco immediato è necessario per prevenire la corruzione di dati nel caso di guasto. I controlli che vengono eseguiti a livello hardware includono anche controlli di parità, di codice, di autotest. Un altro punto di vista di cui bisogna tenere conto è il prezzo, che deve essere in grado di rivaleggiare con i sistemi non tolleranti ai guasti, questo perché i clienti non sono disposti a pagare il doppio o il triplo un sistema, solo perché è tollerante ai guasti.
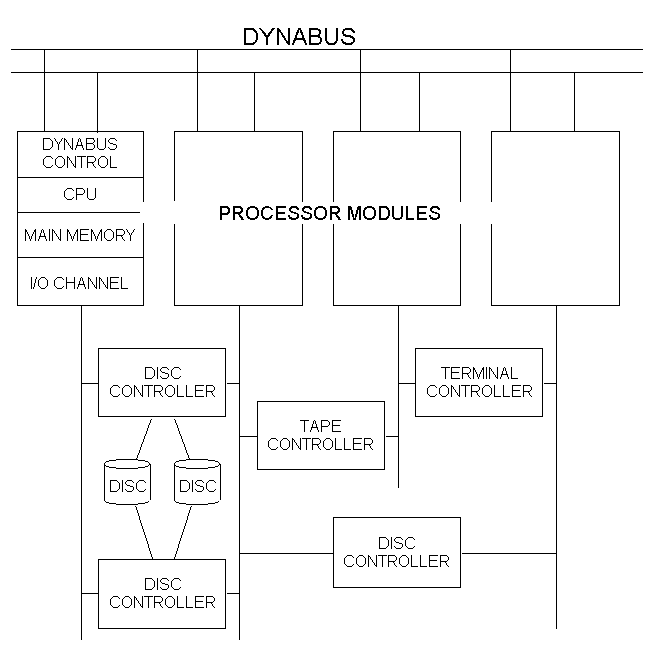
Quella in figura è l’architettura originale del sistema Tandem Non Stop I introdotto nel 1976 come primo sistema FT. Il sistema può avere da 2 a 16 processori collegati da un bus a 13 MByte/sec (Dynabus). Ogni processore ha la propria memoria dove risiede la propria copia del sistema operativo, il proprio bus di I/O. Ogni controller a 2 porte (primaria e secondaria) è collegato a due CPU. Quando avviene un guasto, si passa dal controllore primario a quello secondario, per una determinata periferica, si aggiusta il guasto e poi si riassetta il sistema. Ovviamente in caso di guasto ad un processore, il carico di lavoro restante viene diviso tra i restanti processori. 3.3 CPU Il design di una CPU in un sistema Tandem non è tanto diverso da quello di un processore tradizionale. Ogni processore opera indipendentemente e in modo asincrono dagli altri. L’unica richiesta aggiuntiva è che il guasto su un processore non si propaghi sul Dynabus e danneggi gli altri, quindi appena si rileva un guasto bisogna disabilitare entrambi i bus di quel processore. Inoltre il processore deve disabilitarsi in tempo per evitare di spedire dati incorretti su qualunque bus (Dynabus o I/O bus). Anche se il processore tratta istruzioni di tipo pipeline, questo non è un problema su un sistema tandem, come potrebbe esserlo su un qualunque altro sistema, perché la memoria è locale e non shared. Alcuni sistemi hanno hardware dedicato per ritentare da una istruzione, dopo il suo fallimento; Tandem non lo richiede, ma incorpora questa funzionalità nel processore VLX stesso (1986) nella cache di primo livello e nell’unità di controllo. Inoltre la cache ha una propria RAM che continua a funzionare anche se la RAM di quel processore si guasta. Viceversa la RAM contiene una copia della cache (perché essa è store-through), in caso di errore di parità la cache viene eliminata e si fetcha il contenuto della memoria al suo posto. L’unità di controllo ha due copie, la seconda delle quali viene utilizzata in caso di guasto intermittente al posto della prima. Successivamente sono state introdotte delle estensioni per il supporto di un bus a fibra ottica (FOX), per diverse tipologie di processore. 3.4 Periferiche Anche le periferiche hanno gli stessi principi di modularità, doppio accesso, ecc. dell’hardware di base. L’architettura di base prevede la possibilità di configurare il sistema di I/O in modo da permettere più vie d’accesso alla stessa periferica di I/O. Con un controllore a due porte e una periferica a due porte, si hanno 4 possibili percorsi di accesso. Con un disco duplicato (mirror) si arriva ad avere 8 possibili vie d’accesso che possono essere utilizzate per lettura e scrittura dei dati. Il sistema è cambiato durante gli anni. Da un set di switches per ogni processore, che potevano essere programmati, si è passato ad una vera e propria unità di controllo comandata da uno Z80 (Operation & Service Processor) che comunica con tutto il sistema. L’OSP non è FT, ma se questa diventa un’esigenza, si può passare al sistema CHECK, che consiste in un dual-68000 che comunica con il resto del sistema attraverso un doppio bus. Ogni evento relativo ad un guasto o inaspettato è trattato e memorizzato in un log dal CHECK. Il CHECK comunica con un sistema esperto che gira sul processore principale, il quale analizza il log degli eventi e decide quali azioni intraprendere. In caso di necessità si comunica ad un addetto alla manutenzione ciò che sta avvenendo. I controller delle periferiche hanno gli stessi meccanismi di blocco immediato in caso di guasto come i processori e se possibile devono ritornare al loro processore l’informazione di fallimento. Inoltre i controllori interni devono supportare la rilevazione automatica di errori, oltre naturalmente ai controlli che vengono imposti dai livelli superiori di software. Per un sistema FT il costo delle periferiche dev’essere mantenuto basso, a causa della duplicazione che bisogna mettere in atto. I processi sono l’analogo software dei processori. Sono l’unità di base del software: modularità, servizio, guasto, riparazione. Il kernel del sistema operativo che gira su ogni processore supporta processi multipli, ognuno dei quali può avere uno spazio di indirizzi virtuali di un GigaByte. I processi potrebbero condividere la memoria fisica, ma questo porterebbe al pericolo di non potere più limitare il raggio di azione di un guasto. Quindi si è scelto di far comunicare i processi tramite messaggi, mentre si può condividere solo la memoria in read-only. Il kernel del sistema compie tutte le operazioni di dispatching con classi di priorità, trasmissione di messaggi tra processi, e riconfigurazione in caso di avaria dell’hardware. Il kernel può anche mandare messaggi a processi che sono su un altro processore (quindi ad un altro kernel, che si occuperà della consegna del messaggio), ovviamente il tutto è trasparente sia al trasmettitore che al ricevitore. Soltanto il kernel si occupa del "routing" del messaggio. Se un canale fisico presenta guasti, il kernel si occupa di instradare il messaggio su di un altro canale. Il kernel ha inoltre la possibilità di nascondere alcune avarie hardware. Ad esempio se c’è un errore in una pagina read-only in memoria, si carica semplicemente la pagina corrispondente da disco. Così come un guasto sull’alimentazione porta alla memorizzazione dello stato del processore, per poi recuperare il tutto, quando la riparazione è avvenuta (esistono delle batterie tampone, per questa operazione). A livello di sistema, quando "cade" un processore, gli altri se ne accorgono dopo un massimo di 2 sec. (tempo di trasmissione e propagazione del messaggio "io sono vivo" da parte di un processore), a questo punto viene attivato l’algoritmo di raggruppamento dei processori rimasti, per vedere chi è funzionante e chi no, e per decidere come ridividere i compiti. La tolleranza al guasto singolo, prevede che quando un guasto colpisce un processo (per un baco del software (errore transiente) e per caduta di un processore), l’applicazione continui a funzionare. Per questo si è deciso di implementare una coppia di processi: ogni processo ha una sua copia che "gira" su di un’altra CPU. Il processo di backup ha lo stesso programma, spazio di indirizzi logico e sessioni, come il primario. Quando il primario va in esecuzione, il backup non fa niente; in determinati punti critici, il primario manda al backup il messaggio di "checkpoint", (questo messaggio può assumere varie forme, può essere l’immagine del nuovo stato da raggiungere, o semplicemente una funzione da applicare per raggiungere il nuovo stato). Se il primario fallisce per una qualsiasi ragione, il backup diventa il primario e il kernel gli ridirige tutti i messaggi dall’ultimo checkpoint. Per ottenere la modularità del software, ogni computazione è divisa in più processi. Se un processo esegue una funzione molto particolare, esso può diventare un collo di bottiglia se il sistema cresce. Il concetto di classe di processi server è stata introdotta per evitare questo inconveniente: una classe rappresenta una collezione di processi i quali svolgono tutti la stessa funzione. Questi processi sono di solito ripartiti su più processori e le richieste di servizio sono fatte direttamente alla classe, invece che al singolo processo. Se il carico di lavoro aumenta, vengono semplicemente aggiunti nuovi membri alla classe (il viceversa accade quando il carico diminuisce). 4.4 Files Il sistema di management dei dati, supporta sia files strutturati (es. indicizzati con chiave), che non strutturati. I files strutturati possono avere indici secondari multipli. I files possono essere partizionati su più dischi sparsi nella rete di sistema e ogni partizione è duplicata su un disco mirror. Una classe di processi doppi supervisiona ogni disco. In caso di lettura, se la pagina non è nella cache del disco primario, allora il processo di supervisione trova quale dei due dischi offre l’accesso più veloce, e legge da quello (questo porta ad un risparmio di tempo). La scrittura invece porta ad una perdita di tempo, dovuta al fatto che l’update di un file va effettuato su entrambi i dischi. In aggiunta è possibile instaurare un sistema transazionale per la protezione con log di undo e redo. 4.5 Transazioni Nei sistemi Tandem viene utilizzato il Transaction Monitor Facility (TMF). Il TMF permette ad una applicazione di ottenere un transaction id per ogni particolare job. Tutto il lavoro fatto dal job viene etichettato col transaction id, così come i record di undo e redo. Se tutto va a buon fine, la transazione fa’ il commit, altrimenti si abortisce il tutto. Per alcune particolari applicazione, tutto questo è più semplice del meccanismo di processi doppi. I drivers e il kernel necessitano ancora dei processi doppi, ma questi sono a livello inferiore del TMF (infatti essi sono utilizzati per implementare il protocollo di commit non bloccante). Per maggiori informazioni si rimanda al capitolo sulle transazioni. Il sistema Tandem implementa tutti i classici protocolli two-phase-lock e two-phase-commit, e i log oltre ad avere una doppia copia del database. Per quanto riguarda i costi, implementare un sistema transazionale comporta un aumento del 10%, ma permette anche di far fronte a guasti multipli.
Il principio di base che sta a livello alto di astrazione è che più semplice è il sistema, più è facile che l’utente non commetta errori. Si sono introdotte quindi interfacce utente di tipo grafico, supporto per database relazionali, e supporto ai maggiori linguaggi di programmazione. Il sistema di sviluppo delle applicazioni presenta una semplice interfaccia a menù, guida passo – passo lo sviluppatore e dove possibile crea già il codice e i meccanismi transazionali. 6. Manutenzione Il sistema Tandem cerca per quanto possibile di eliminare l’intervento umano, perché esso può essere causa di altri problemi (ad esempio perché si è fatta una scelta errata basata su dati insufficienti). Le operazioni di routine sono gestite automaticamente e in caso di guasto singolo hardware il sistema si riconfigura in modo autonomo. All’operatore umano vengono lasciate tutte le operazioni di gestione di situazioni eccezionali, il tutto dando un modello di astrazione di alto livello del sistema. L’interfaccia in questo caso è sotto forma di rapporti di eccezioni e di azioni. É possibile anche un diagnostico passo – passo che permette all’operatore di riparare il guasto. Per quanto riguarda la manutenzione, in teoria essa non dovrebbe essere necessaria, in un sistema simile. In pratica la manutenzione consiste nella diagnosi di un guasto e nella sostituzione di un’unità di sistema (Field Replaceable Unit). Inoltre è possibile tenere traccia della storia di ogni singola FRU.
|