|
|
|
|
1. Introduzione In questo capitolo presenteremo tutte le proprietà e i benefici della sincronizzazione, al fine di mostrare come si può creare un sistema FT distribuito basato sulla sincronizzazione a più livelli e la ridondanza dei componenti come primo stadio per poi creare un completo sistema FT [8]. L’interazione tra componenti è richiesta ad un qualsiasi livello di FT: ricerca di errori, recupero, confinamento dell’errore, votazioni, riconfigurazione, mascheramento dell’errore, ecc.. se poi il sistema deve soddisfare anche altri requisiti stringenti come: operazioni real time, tempo di recupero minimo, numero massimo di errori tollerati, ecc.. si nota sicuramente un aumento delle informazioni scambiate tra i vari componenti del sistema e un bisogno di sincronizzazione, a maggior ragione se il sistema in questione è distribuito. Un sistema così complesso, sarà strutturato sicuramente a livelli gerarchici, quindi è quasi naturale cercare di costruire il sistema in modo che ci sia anche un livello gerarchico di sincronizzazione, attraverso il quale i componenti (anche ridondanti) possano costituire la base di un qualsiasi schema di FT successivo. 2. Sincronizzazione e ridondanza La ridondanza è il primo modo per fare FT hardware. In caso di guasto di un componente, esso viene mascherato e viene fatto partire un altro componente identico al posto di quello guastato. Si può pensare di estendere questo concetto a qualsiasi componente, non solo risorsa hardware. Chiamiamo la sincronizzazione delle operazioni di software, hardware ridondanti (per un qualsiasi scopo di FT) RS (redundancy synchronization ). Con l’aiuto di RS, un componente di alto livello (ad esempio un utente del Distributed Operating System) ha risorse virtuali FT a sua disposizione (una per ogni tipo, invece di molte), e lo scopo di RS è quello di sincronizzarle tutte (condizione essenziale, ad esempio, per un qualsiasi tipo di recupero in seguito a errore). RS è essenziale per i seguenti motivi:
Non è richiesto il fatto che i componenti ridondanti siano identici, ma che svolgano lo stesso servizio e che i loro stati siano coordinati. Ad esempio in caso di ridondanza software, ogni componente può essere stato sviluppato indipendentemente dagli altri, ma ognuno di essi deve fornire la medesima interfaccia al livello superiore. Non è nemmeno necessario che il componente ridondante sia utilizzato per rimpiazzare direttamente quello guasto, se lo schema di FT utilizzato prevede la votazione o la media dei risultati. D’altra parte i componenti software o misti HW-SW possono utilizzare uno schema di rimpiazzamento in stand-by (come per l’hardware) così una volta che l’informazione è stata salvata, si passa al componente ridondante che viene sincronizzato e fatto partire come se fosse l’originale. In un sistema reale distribuito, tutte le risorse HW e SW saranno trattate in modo uguale dal sistema di sincronizzazione, in questo modo si rende la ridondanza trasparente agli utilizzatori del DOS. L’RS è implementato in questo modo: Controllo di processi ridondanti e CPU ridondanti: questo è conosciuto come replicazione dei processi: più copie dello stesso programma sono eseguite simultaneamente (in diversi nodi). La sincronizzazione in questo caso è attraverso l’invio di messaggi. Controllo di nodi ridondanti (computer): questo è necessario quando c’è del software identico che "sta girando". Il risultato finale o i vari risultati intermedi devono essere sincronizzati, utilizzando clock comune, ciclo di bus comune. Controllo di periferiche ridondanti: è usata solo con l’uso di operazioni riguardanti le periferiche. Esempio: i dischi shadow. Controllo di più input o output: può essere fatto sincronizzando le entrate e facendo voti sulle uscite. Controllo di files ridondanti: essi sono sempre sincronizzati qualsiasi operazione si faccia su essi: è la base per costruire file shadow. Controllo di timer ridondanti: può essere visto allo stesso modo del problema di sincronizzare dati in input; è più complicato perché implica la necessità di avere un tempo globale per il DOS e le applicazioni.
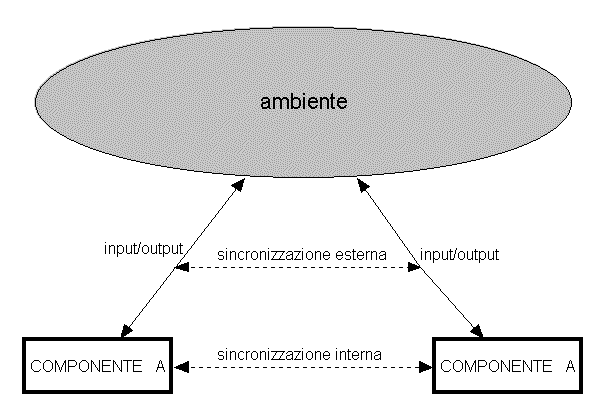
Come si vede da figura, esistono 2 tipi di sincronizzazione: interna ed esterna. Quella esterna si riferisce alle procedure chiamate, ai dati di in e out, ai dati richiamati dalla memoria, ecc.. Quella interna si riferisce al match dei risultati intermedi, ad esempio. L’RS è efficiente quando c’è un sufficiente numero di elementi che sono nello stato di lavoro e lo segnalano entro un limite di tempo accettabile. Ci possono essere casi in cui l’RS non può essere fatto a questo livello, per vari motivi: tutti gli elementi ridondanti sono guasti, non ci sono segnali per un lungo periodo di tempo... quindi bisogna utilizzare un livello superiore di risorse. Ad esempio se entrambi i dischi di un sistema shadow si guastano, allora bisognerà utilizzare un altro computer, che andrà sincronizzato con le operazioni del primo computer. Ovviamente tutto il sistema di sincronizzazione deve essere gestito da qualcuno: di solito un server (RSS). Ogni componente deve stabilire un punto di sincronizzazione (SP) con il server (il protocollo per questa operazione è a livello software). Il RSS riceve le informazioni su tutti i componenti, prima di far partire il sistema. L’algoritmo di sincronizzazione differisce sostanzialmente a seconda delle risorse in funzione (come visto esistono varie politiche). L’RSS stabilisce (oppure concorda) quale risorsa è primaria e quali sono ridondanti, quali sono i lassi di tempo necessari e quali scarti accettati, i tempi di risposta delle applicazioni di sistema. Per quanto riguarda l’ingegneria del software da applicare al design di un sistema simile, bisogna tener conto innanzitutto di tutti i guasti probabili e su quali componenti, un lista di questo genere già di per sé compone la lista di gerarchia da applicare. Stabilire l’algoritmo da mettere in atto per il recupero in caso di guasto. Tener conto del fatto che dopo un’operazione di sincronizzazione esterna, può essere necessario un filtraggio dei dati di applicazione per i componenti a valle. (questa parte deve essere scritta dai programmatori delle applicazioni).
|