|
|
|
|
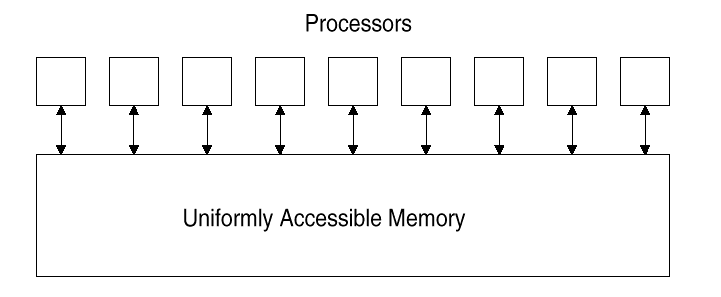
Computazione parallela su una rete di workstations 1. Introduzione Il principio di base di computazione ad alto rendimento è di permettere l’esecuzione parallela andando a minimizzare l’overhead introdotto. Tale computazione è solitamente eseguita da hardware costoso e dedicato, che è spesso progettato su misura. Tuttavia, negli ultimi anni si è sempre più utilizzato hardware distribuito a basso costo in grado di eseguire calcoli paralleli. Questo paragrafo descrive un nuovo metodo per sfruttare la potenza delle workstations per computazioni parallele che richiedono alta performance [14]. Recentemente, nuovi risultati teorici hanno fornito delle tecniche precise che permettono ad una macchina convenzionale, modellata come un multiprocessore asincrono (con memoria comune), di eseguire efficientemente i programmi paralleli. Intrinsecamente, questi algoritmi, con alcune modifiche, sono adatti a essere utilizzati per il calcolo parallelo su una rete di workstations. Oltre al calcolo parallelo si introduce in modo naturale il concetto di tolleranza ai guasti e di load balancing. L’approccio proposto ha come scopo quello di permettere l’esecuzione parallela di un programma riscrivendolo il meno possibile, in modo che il parallelismo e la fault tolerance siano caratteristiche intrinseche del sistema. Vengono definite due macchine: la macchina ideale M presentata al programmatore e la più realistica macchina MR che è usata per eseguire i programmi scritti per M. Le tecniche formali sono usate per passare in modo automatico dal programma scritto per M all’esecuzione su MR. La macchina ideale M presentata al programmatore è una macchina sincrona con memoria condivisa e con un numero illimitato di processori virtuali (vedi figura).
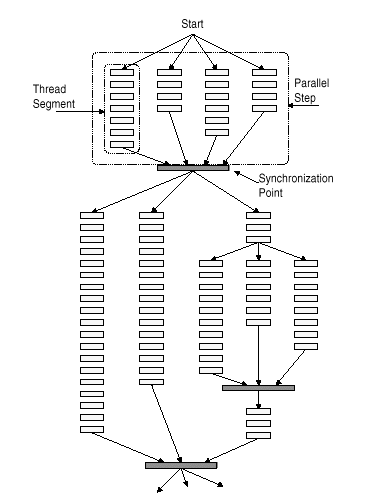
Il programmatore scrive un programma parallelo ideale che consiste in una sequenza di passi paralleli. In ogni passo parallelo un certo numero di threads vengono eseguiti in parallelo, ognuno su un processore ad esso dedicato. Un passo parallelo termina quando tutti i threads hanno completato la loro esecuzione, poi il passo successivo inizia (vedi figura).
La macchina realistica MR ha un numero finito di processori completamente asincroni con una memoria condivisa a cui tutti i processori possono accedere. Ogni istruzione può richiedere un’illimitata quantità di tempo per essere completata (un guasto al processore è un caso particolare). Le uniche istruzioni atomiche sono quelle di read e write dalla memoria. L’esecuzione è una sequenza di passi paralleli, logicamente numerati 1, 2, …, etc. Il clock logico memorizza il numero del passo corrente. Un processore libero di MR si schedula da solo (eager scheduling) catturando una copia del thread non ancora concluso nel corrente passo parallelo. Il thread viene quindi eseguito: lettura delle variabili, computazione, scrittura delle variabili. Un passo parallelo termina quando tutti i thread sono stati completati, a questo punto il clock viene incrementato. Per garantire una corretta esecuzione, ogni thread deve essere eseguito logicamente una ed una sola volta, questo viene garantito dalla CertifiedTouchAll: durante ogni passo, una struttura dati è utilizzata per tenere traccia dei thread che sono stati eseguiti. Viene utilizzato un efficiente algoritmo con complessità O(log n). Vediamo quali sono alcune delle caratteristiche introdotte:
Nel seguito si faranno le seguenti assunzioni:
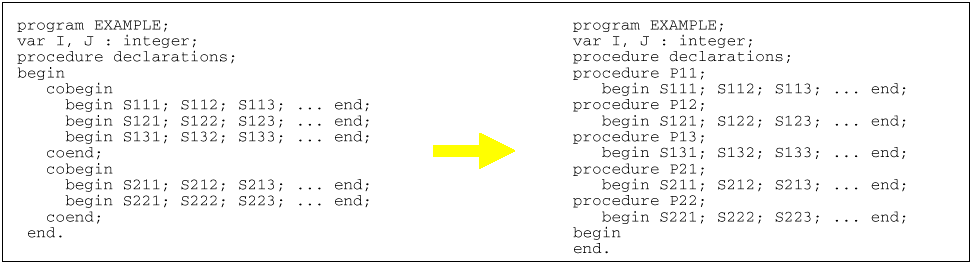
3.1 Compilazione Il programma parallelo è scritto in un linguaggio che supporta il parallelismo. Il programma è pre-processato in un programma sequenziale in un linguaggio standard, che viene poi compilato con un normale compilatore. Un passo parallelo è individuato dal blocco cobegin – coend, e un thread dal blocco begin – end (un esempio in pseudo Pascal è riportato nella parte sinistra della figura).
Il pre-processing trasforma il programma iniziala togliendo i cobegin – coend, sostituendo i begin – end con delle procedure globali ed eliminando tutto il main (si veda la parte destra della figura). A questo punto il codice trasformato viene compilato da uno compilatore sequenziale standard ottenendo il codice oggetto, viene anche creta una tabella Progress Table estraendo il punto di partenza di ogni procedura dalla tabella dei simboli generata dal compilatore. La struttura della Progress Table è la seguente:
Il codice oggetto e la Progress Table vengono memorizzati sul memory server, che è un sistema in grado di memorizzare il programma e i suoi dati e spedirli sulla rete alle varie workstation. Nella prima versione si assume che il memory server sia stabile (non cada mai), successivamente questa limitazione verrà eliminata e, quindi, si tollereranno anche i guasti nel memory server.
3.2 Memory service ed esecuzione La Progress Table, oltre che il punto di inizio delle procedure (thread), indica anche se i thread sono iniziati e/o terminati. Ogni compute server ha un worker daemon che è in grado di ottenere informazioni dalla Progress Table. Quando un compute server esamina la Progress Table segue il seguente algoritmo (in mutua esclusione):
L’esecuzione del thread lavora sulla copia scaricata in locale della memoria, solo alla fine della computazione tutte le modifiche fatta alla memoria vengono registrate nella memoria condivisa dal memory server che, a questo punto, registra nella Progress Table la terminazione (campo "done?") del thread. Così ogni workstation sottoutilizzata può eseguire lo stesso thread (per esempio si può eseguire un thread non ancora terminato, ma tutti gli altri thread del passo parallelo precedente sono stati portati a termine). Questo è il punto principale dell’eager scheduling ed è anche il meccanismo che introduce la tolleranza ai guasti. Si notino le seguenti proprietà del sistema:
In realtà bisogna arricchire e complicare il sistema in modo che funzioni correttamente. Il problema maggiore si ha con la memoria. Si supponga che un compute server A sia molto lento e che il compute server B rimpiazzi A finendo l’esecuzione del thread. Il passo parallelo sarà così completato e la computazione passerà al passo successivo. Più tardi, però, A completerà il suo thread e andrà a scrivere in memoria i risultati ottenuti andando a rovinare il contenuto della memoria. Un altro punto importante è quello di avere una memory server affidabile. Si costruisce, quindi, un memory server da un insieme di memory server replicati, questo comporta, però, l’introduzione di un forte overhead ad ogni operazione di lettura e scrittura. Questo inconveniente viene risolto andando a disperdere le variabili nella memoria condivisa, l’indirizzo della variabile cambia ogni volta che essa viene scritta (è più conveniente della replicazione). Questo compito viene svolto dal progress manager.
3.3 Conclusioni I classici sistemi tolleranti ai guasti replicano i dati e la computazione, introducendo un significativo overhead nell’esecuzione se non si presentano guasti. L’approccio qui proposto invece per garantire l’integrità dei dati utilizza la dispersione che è meno costosa della replicazione. Inoltre la computazione non è replicata nei modo convenzionali, solo quando l’esecuzione di un thread diventa lenta e ci sono dei compute server disponibili un'altra esecuzione del thread viene fatta partire.
|