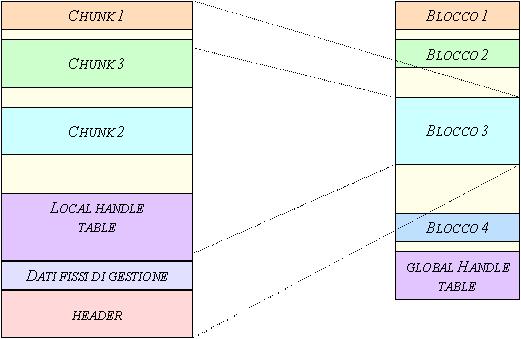
Figura 10: struttura di uno heap locale.
CAPITOLO 8:
GESTIONE DELLA MEMORIA LOCALE
Il gestore della memoria lavora in modo ottimale quando i blocchi hanno dimensione di 26 K, ma quando si devono usare piccole parti di questi blocchi i problemi di overloading diventano significativi: per questo si hanno delle routine per gestire la memoria locale; è, infatti, possibile allocare un blocco di memoria e designarlo come un Local Memory Heap, allinterno di questo, poi, le applicazione potranno allocare parti di memoria più piccole. Queste routine sono, anche, usate per manipolare gli oggetti.
La problematica che determina lintroduzione della memoria locale è che GEOS permette solo luso di un numero limitato di global handle: se unapplicazione ha usato i blocchi per piccole quantità di dati, potrebbe usare troppi handle. Daltra parte, la memorizzazione di molti piccole pezzi di dati in un unico blocco globale da parte della stessa applicazione potrebbe richiedere routine di gestione della memoria molte complicate.
Una volta che un blocco è stato scelto per essere un local heap, in esso possono essere memorizzate piccole quantità di dati, che possono essere spostate al suo interno per soddisfare altre richieste.
Un vantaggio notevole introdotto con la memoria locale è la possibilità
di trattare in modo uniforme le piccole porzioni di memoria.
8.1: Struttura del local heap
Uno heap locale di memoria appare e si comporta come uno globale, la differenza sta nel fatto che uno heap localeè completamente contenuto in un solo blocco globale. Questo blocco viene inizializzato con uno header di 16 byte, una Local Memory Handle Table e un local heap memory; potrebbe essere allocata della memoria per dati anche tra lo header e la handle table per contenere dati extra.
Ogni sezione di memoria allinterno dello heap locale è chiamato chunk e il suo handle chunk handle. Un chunk comprende la parte di dati da memorizzare preceduta da una sezione in cui viene indicata la sua lunghezza in bytes. Quando viene creato uno heap locale viene allocato un certo numero di chunk handle: se viene richiesto un chunk dopo che tutti quelli presenti sono stati assegnati, ci sono delle routine che si occupano di allargare la local handle table, rilocando i chunk presenti, se necessario; i chunk non usati vengono memorizzati in una lista collegata.
Il blocco globale da far diventare heap locale può essere fixed, swapable o discardable: quello che è importante osservare è che un blocco può contenere altri dati oltre il local heap. Al momento della creazione di un nuovo local heap, la sua posizione allinterno deve essere definita attraverso un parametro (in questo caso un offset); a questo punto lo heap definisce e alloca la struttura dello header e la handle table (alloffset specificato); lo spazio tra queste due parti resta "intoccabile" per le routine che si occupano della gestione di questo tipo di memoria. Loffset deve essere più grande dello header oppure zero (in questo caso va usato loffset di default).
La figura 10 mostra graficamente la struttura di un local heap in corrispondenza di un blocco globale.
Prima di fare una qualsiasi operazione sul local heap, unapplicazione deve avere un lock sul blocco che lo contiene come avviene per un qualsiasi altro blocco; in questo modo si possono evitare problemi di sincronizzazionedovuti alla richiesta ( da parte di altre routine) di un ridimensionamento dello heap e/o di un eventuale spostamento del blocco allinterno della memoria globale; è possibile definire uno heap locale impedendo operazioni di ridimensionamento (questo soprattutto quando lo heap viene definito su un blocco di tipo fixed).
Figura 10: struttura di uno heap locale.
Come è stato già detto in precedenza laccesso ai chunk avviene attraverso degli handle (chunk handle): questi rappresentano loffset, allinterno del blocco globale, a partire dal quale è stato memorizzato il chunk in questione. Lindirizzo del segmento dello heap bloccato, combinato con il chunk handle, fornisce un puntatore ad una cella della local handle table; quando viene, poi, combinato il contenuto di tale cella (loffset del chunk nel blocco globale) con il suo indirizzo (appena calcolato) si ottiene un puntatore al chunk attuale.
La figura 11 (nella pagina seguente) schematizza questo modo di accedere ai chunk.
I chunk possono essere spostati allinterno dello heap: questoperazione può accadere ogni qual volta il sistema crea o ridimensiona un chunk. Non esiste un meccanismo di locking per i chunk: ogni operazione che porta alla modifica o allo spostamento di un chunk, può, potenzialmente, invalidare i puntatori a tutti gli altri chunk e forzare, conseguentemente, lapplicazione a dereferenziare gli handle per il chunk che sta usando (per conoscerne la nuova locazione).
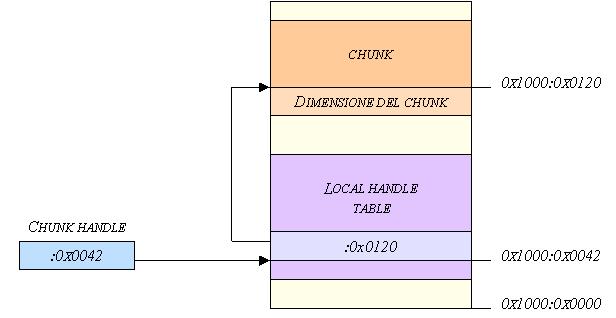
Figura 11: modo di riferirsi ad un chunk.
Per ovviare a questi inconvenienti sarebbe opportuno seguire la regola generale secondo cui non bisognerebbe salvare un chunk mentre circolano dei messaggi nel sistema e si dovrebbe dereferenziare il chunk handle ogni volta che si vuole ottenere lindirizzo corrente del chunk.
I chunk vengono ordinati in base alla lunghezza della loro area dati, in modo da accelerare le operazioni di spostamento dei chunk stessi: può, quindi, capitare di ottenere un chunk leggermente più grosso di quello richiesto.
Gli oggetti sono dei tipi particolari di chunk; un Object pointer non è altro che una coppia di handle: quello per individuare un blocco nella memoria globale e quello per individuare un chunk allinterno di un determinato blocco globale.
Lo heap locale ha vari usi, oltre a quello legato alla gestione della memoria: per questo quando si crea un nuovo heap locale bisogna passare, anche, un parametro di tipo enumerativo con cui viene specificato luso cui è destinato lo heap appena creato. Tra i tipi duso possibili ci sono:
8.2: Uso della memoria locale
Molte applicazioni non hanno bisogno di usare i local heap direttamente; nonostante ciò avranno bisogno di usare meccanismi di gestione dei dati basati su local heap.
La creazione di un local heap è preceduto da due operazioni: lallocazione e il locking di un blocco nel global heap; la routine che si occupa della creazione e dellinizializzazione del local heap ha bisogno di parecchi parametri in ingresso come:
La routine che si occupa di allocare nuovi chunk dà come risultato il loro handle; la dimensione di tali chunk viene controllata spesso in modo da garantire lordinamento in base alla lunghezza dellarea dati dei chunk: questoperazione può comportare un compattamento del local heap che potrebbe invalidare tutti i puntatori di quello heap; in questottica possono essere spostati anche i blocchi fixed se questo è necessari per espanderli e allocarvi allinterno nuovi chunk.
Ovviamente, come accade per i blocchi globali, una volta allocato un nuovo chunk bisogna dereferenziare il suo handle per poterlo utilizzare: il puntatore che si ottiene come risultato rimarrà valido finché il lock sul blocco non viene rilasciato o finché non viene chiamata una routine che causa una compaction dello heap o un ridimensionamento del blocco. È molto importante usare le routine che garantiscono la sincronizzazione dei dati quando più thread accedono allo heap dal momento che alcune delle routine che possono lanciare gli altri thread, che lavorano sullo stesso heap, potrebbero invalidare i puntatori.
È già stato detto come i chunk possono essere ridimensionati dopo la loro creazione. Se la nuova dimensione è più grande della precedente, il chunk viene ingrandito sistemando alla fine la parte da aggiungere. Per poter fare questa operazione deve essere possibile spostare il chunk allinterno dello heap oppure ridimensionare il blocco globale stesso, ma queste azioni porterebbero il sistema ad invalidare tutti i puntatori dello heap. La parte nuova non viene inizializzata impostando i bytes a zero. Se, al contrario, la nuova dimensione è più piccola della precedente, il chunk viene troncato senza invalidare i suoi puntatori. Nel caso in cui lo heap non sia ridimensionabile le routine che gestiscono questi aspetti falliscono.
È possibile anche aggiungere e cancellare bytes ad un determinato
offset allinterno del chunk: nel caso dellinserimento (a differenza della
cancellazione) il chunk va espanso e quindi si potrebbero avere i puntatori
invalidati; in questo caso, però, i bytes che vengono aggiunti sono
inizializzati a zero.
8.3: Chunk array
Molto spesso unapplicazione ha bisogno di tener traccia di differenti pezzi di dati e accedervi attraverso un indice. A questo scopo viene messo a disposizione un meccanismo adatto: i chunk array. Le routine che si occupano della gestione dei chunk array permettono di aggiungere o cancellare dinamicamente elementi che si trovano allinterno dellarray, di avere un puntatore ad un determinato elemento specificato dal suo indice, di ordinare larray secondo dei criteri scelti arbitrariamente.
I chunk array possono avere:
I chunk array sono implementati in testa alle routine della memoria locale; lintero array è visto come un singolo chunk nello heap locale. Le dimensioni di tali array devono aggirarsi intorno ai 6K perché la memoria venga gestita efficientemente, nel caso di array più grandi (che non devono superare i 64K) si ricorre alluso di huge array.
Un chunk array è composto da:
La struttura di un chunk array cambia a seconda delle caratteristiche
degli elementi che contiene.
8.3.1: Array a dimensione uniforme
Nel caso di array a dimensione uniforme la struttura è piuttosto semplice: dopo lo header e lo spazio extra vengono direttamente gli elementi; questi si susseguono uno dopo laltro senza lasciare spazio tra uno e laltro. Unapplicazione può richiedere un puntatore a qualsiasi elemento specificando lindice: questo è ottenuto moltiplicando lindice per la dimensione (fissa) di ciascun elemento e aggiungendo il tutto allindirizzo del primo elemento. Questo non toglie la possibilità di avere un accesso sequenziale agli elementi dellarray, passando da un elemento al successivo senza dover richiedere specificatamente un puntatore.
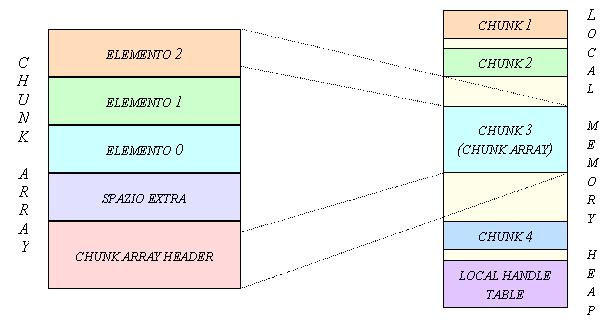
Figura 12: chunk array a dimensione uniforme
8.3.2: Array a dimensione variabile
La struttura di unarray a dimensione variabile è leggermente più complessa. Dopo lo header e lo spazio extra viene allocata una look-up table con entry di due bytes che contengono loffset dallinizio del chunk allo specifico elemento; questa tabella viene mantenuta automaticamente dalle routine di gestione dellarray.
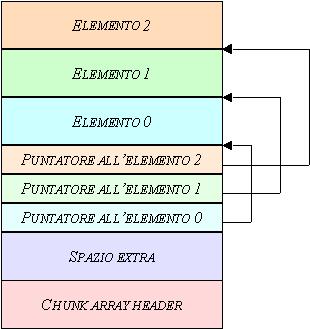
Figura 13: chunk array a dimensione variabile
Quando unapplicazione vuole riferirsi ad un certo elemento la routine
addetta allaccesso allarray raddoppia lindice dellelemento cui accedere
e somma il tutto alloffset tra linizio del chunk e quello della look-up
table: in questo modo si produce lindirizzo ad una entry della tabella
che contiene loffset per raggiungere lelemento corrente. Si può
notare come unarray a dimensione variabile contenga due array con lo stesso
numero di elementi: uno a dimensione uniforme (la look-up table) e uno
a dimensione variabile (linsieme degli elementi dellarray). Questa caratteristica
è trasparente allapplicazione che non fa altro che chiedere un
puntatore alln-esimo elemento.
8.4: Element array
Molte volte è necessario creare un array con un alto tasso di duplicazione, quindi siamo di fronte ad un array che contiene molti elementi identici. La normale gestione diventa inefficiente quando il tasso di duplicazione è molto alto, per ovviare a questi inconvenienti di gestione si introducono gli element array: ogni elemento dellarray ha un reference count (contenuto nello header). Quando viene inserito un nuovo elemento la routine che si occupa dellinserzione controlla se un altro elemento identico è già presente nellarray; se il risultato è positivo non viene introdotta una nuova copia dellelemento, ma viene incrementato il reference count dellelemento già presente e viene ritornato il suo indice; se, invece, non esiste un altro elemento identico nellarray questo viene copiato nellarray, viene fissato a 1 il suo reference count e viene ritornato il suo indice.
Gli elementi di questo tipo di chunk array possono essere fissi, di dimensione uniforme o variabile: in ogni caso va indicata la dimensione degli elementi allatto della creazione dellarray (tale valore sarà zero nel caso di array a dimensione variabile).
Tutti gli elementi di un element array mantengono il loro indice finchè non vengono liberati; quando un elemento viene cancellato, le routine di gestione ridimensionano lelemento a zero e lo aggiungono ad una lista degli elementi da liberare. Questo significa che, a differenza dei chunk array, lelemento con indice 12 potrebbe non essere il tredicesimo elemento dellarray, perché potrebbero esserci degli elementi liberati prima; per questo motivo con gli element array si parla di token e non di indici; i token, infatti, sono considerati come dei valori opachi.
Ogni qual volta si cancella il riferimento ad un elemento, il suo refernce count viene decrementato, quando raggiunge il valore zero lelemento corrispondente viene eliminato fisicamente dallarray.
Linserimento richiede una ricerca (con costo lineare) tra gli elementi
esistenti nellarray: questo tipo di array diventa inefficiente da gestire
quando contiene molti elementi e si continua ad aggiungerne di nuovi. Laccesso
agli elementi, invece, richiede un tempo costante, se le routine di gestione
riescono a tradurre velocemente il token di un elemento nel corrispondente
offset.
8.5: Name array
I name array sono tipi particolari di element array nei quali si può accedere agli elementi sia attraverso il token sia usando unetichetta (nome) associata in modo univoco ad ogni elemento.
I name array hanno elementi con dimensione variabile, questi sono composti da tre parti: